

Τεχνητή Νοημοσύνη - Μέρος Β
Β1. Βασικοί τομείς εφαρμογής συστημάτων Α.Ι
Οι νέες τεχνολογίες τεχνητής νοημοσύνης που αναπτύσσονται αναμένεται να έχουν σημαντικό αντίκτυπο στους παρακάτω τομείς:
(α) ανάπτυξη λογισμικού [1][2][3]
Η συμβολή στον τομέα αυτό αναμένεται σημαντική. Όμως, πρέπει να τονίσουμε ότι οι προσδοκίες πολλών φαίνεται ότι ξεπερνούν κατά πολύ την πραγματικότητα. Τα εργαλεία τεχνητής νοημοσύνης θα αυξήσουν την παραγωγικότητα των προγραμματιστών, αλλά όχι μόνο δεν μπορούν να τους αντικαταστήσουν αλλά και δεν αναμένονται τεκτονικές αλλαγές στην αγορά εργασίας. Αυτό οφείλεται στο ότι ο τελικός έλεγχος και η έγκριση του κώδικα που δημιουργούν αυτά τα εργαλεία θα πρέπει να γίνει από τους προγραμματιστές για να αποφευχθούν προβλήματα ασφάλειας, προβλήματα στην κατανόηση των προδιαγραφών, λογικά σφάλματα στην υλοποίηση των προδιαγραφών κ.α. Επίσης, θα πρέπει να ελέγχεται η πολυπλοκότητα που εισάγει το AI στο λογισμικό μας, ώστε να μπορούμε να επέμβουμε σε αυτό, αν και όποτε χρειαστεί. Για να τα κάνουμε όλα αυτά, η χρήση AI για την παραγωγή κώδικα θα πρέπει να είναι λελογισμένη. Κανείς δεν μπορεί να κάνει ικανοποιητικό έλεγχο σε μια αλλαγή 1.000 ή 5.000 γραμμών κώδικα. Ακόμα και για τα τμήματα του λογισμικού που θα μπορούσαν να φτιαχτούν με εργαλεία τεχνητής νοημοσύνης απαιτείται πολλές φορές μια τεχνική εξειδίκευση από τον χρήστη, γιατί η σύνθεση μιας καλής περιγραφής του τι θέλουμε να μας φτιάξει το εργαλείο τεχνητής νοημοσύνης δεν είναι τόσο απλή διαδικασία.
Επίσης, υπάρχουν τομείς (π.χ. λογιστική και χρηματοοικονομικά, έλεγχος συγκοινωνιών, ασφάλεια επικοινωνιών, έλεγχος λειτουργίας μεγάλων μηχανημάτων) που η τυχαιότητα, η οποία είναι έμφυτη στα εργαλεία τεχνητής νοημοσύνης που χρησιμοποιούν νευρωνικά δίκτυα, δεν έχει θέση· και όλες οι ενέργειες που εκτελούνται από το λογισμικό θα πρέπει να εκτελούνται βάσει προδιαγραφών και να έχουν σαφές και προκαθορισμένο αποτέλεσμα. Μπορεί το AI να βοηθάει στην ανακάλυψη ύποπτων μοτίβων στα δεδομένα ή να προτείνει ενέργειες, αλλά οι ενέργειες καθαυτές θα πρέπει να είναι σαφείς και ντετερμινιστικές. Άρα, προϋποθέτουν κλασσικούς αλγορίθμους και όχι «μαύρα κουτιά» με απρόβλεπτη έξοδο. Πόσο μάλλον όταν αυτά τα μαύρα κουτιά δεν αμφιβάλουν ποτέ για τον εαυτό τους και άρα δεν έχουν ενδοιασμούς, ούτε διπλοσκέφτονται, μια αλλαγή ή ενέργεια που πρόκειται να κάνουν σε κάποιο κρίσιμο τμήμα του συστήματος.
(β) αναζήτηση πληροφορίας και ενημέρωση
Στην πραγματικότητα, τα chat bots (που στηρίζονται στα LLMs), είναι εργαλεία αναζήτησης τα οποία ενσωματώνουν δυνατότητες σύγκρισης διαφόρων πηγών και σύνθεσης της πληροφορίας στην επιθυμητή μορφή. Εκ των πραγμάτων, ένα μέρος της υπηρεσίας που προσέφεραν μέχρι τώρα οι μηχανές αναζήτησης (π.χ. Google Search) θα περάσει σε chat bots όπως το ChatGPT (OpenAI), το Grok (xAI), το Gemini (Google), το Perplexity (Amazon, NVDIA) και άλλα.
(γ) αυτό-οδηγούμενα οχήματα (αυτοκίνητα, πλοία, ...) [4][5][6][7][8]
Κατ’ αρχάς, δεν πρέπει να μπερδεύουμε τη λειτουργία Autopilot, η οποία είναι απλά ένα σύστημα cruise control (π.χ. σου επιτρέπει να αφήσεις το τιμόνι για αρκετή ώρα ή να απομακρύνεις το πόδι σου από το πετάλι διατηρώντας σταθερή ταχύτητα όταν οδηγείς σε μεγάλους αυτοκινητόδρομους με μικρή κίνηση, όπου η αλλαγή πορείας ή λωρίδας είναι σπάνια), με τη λειτουργία FSD (Full Self-Driving), η οποία είναι εντελώς αυτόνομη οδήγηση του αυτοκινήτου (ακόμα και χωρίς παρουσία οδηγού).
Το κομμάτι της αναγνώρισης του περιβάλλοντος (πού βρίσκονται τα όρια του δρόμου, πόσες λωρίδες υπάρχουν και ποια είναι τα όριά τους, αν υπάρχει αντίθετο ρεύμα, αναγνώριση αντικειμένων όπως πινακίδες, φωτεινοί σηματοδότες, αυτοκίνητα κ.λπ.) γίνεται σε μεγάλο βαθμό από ένα σύστημα νευρωνικών δικτύων το οποίο έχει εκπαιδευτεί κατάλληλα. Για να μπορέσουν να αναγνωρίσουν όμως το περιβάλλον οδήγησης, τα συστήματα FSD χρειάζονται πληροφορία γι’ αυτό, την οποία λαμβάνουν από κάμερες, ραντάρ και Lidar (οπτικά ραντάρ). Το κάθε ένα προσφέρει συγκεκριμένα πλεονεκτήματα (εμβέλεια, ακρίβεια απεικόνισης, λειτουργία υπό ακραίες καιρικές συνθήκες κ.ά.), και γι’ αυτό, συνήθως, χρησιμοποιείται ένας συνδυασμός από αυτά. Υπάρχει όμως και ένα σημαντικό τμήμα, το οποίο αφορά θέματα ασφάλειας και συμμόρφωσης με τον κώδικα οδικής κυκλοφορίας, το οποίο υλοποιείται με κλασσικούς αλγορίθμους, γιατί, σε αυτό το κομμάτι, δεν μπορούμε να δεχτούμε τη στοχαστικότητα των αποφάσεων που συνοδεύει το «μαύρο κουτί» ενός νευρωνικού δικτύου. Έτσι, η χάραξη πορείας (λήψη πληροφορίας από online χάρτες, βελτιστοποίηση διαδρομής κ.λπ.), η διατήρηση κατάλληλων αποστάσεων από άλλα οχήματα, ο περιορισμός κινήσεων ή ταχύτητας με βάση τα σήματα, η προτεραιότητα κατά την κίνηση οχημάτων, η ένταση του φρεναρίσματος που απαιτείται κ.ά., βασίζονται σε συγκεκριμένους κλασσικούς αλγορίθμους όπου τα αποτελέσματα μπορούν να προβλεφθούν.
Τα βασικά προβλήματα που αντιμετωπίζουν τα σύγχρονα FSD σχετίζονται κυρίως με ενοχλητική ή "ανόητη" συμπεριφορά του FSD, η οποία μπορεί να συμβεί σε ειδικές περιπτώσεις, αλλά συνήθως δεν είναι επικίνδυνη. Για παράδειγμα, η χάραξη πορείας βασίζεται σε μεγάλο βαθμό στους online χάρτες, οι οποίοι συχνά δεν είναι επικαιροποιημένοι για έργα και οδικές αλλαγές (π.χ. μονοδρόμηση), οπότε μπορεί να επιλεχθεί μια πορεία η οποία να μας ταλαιπωρήσει/καθυστερήσει. Το FSD δεν είναι εύκολο να αντιληφθεί τι συμβαίνει και να αποφασίσει να ζητήσει επανασχεδιασμό της πορείας. Επίσης, το FSD δυσκολεύεται να χειριστεί ειδικές περιπτώσεις που απαιτείται μια μανούβρα, η οποία υπό κανονικές συνθήκες θα ήταν αντικανονική ή παράνομη, αλλά η συγκεκριμένη στιγμή την απαιτεί επειδή έχει συμβεί κάτι (κατολίσθηση, ατύχημα, ειδικές καιρικές συνθήκες). Έτσι, μπορεί να καταλήξουμε με ένα όχημα το οποίο θα μείνει ακινητοποιημένο σε ένα σημείο περιμένοντας μια κατάσταση να επιλυθεί από μόνη της.
Παρόμοιες είναι οι εξελίξεις και στον τομέα της αυτόνομης οδήγησης για φορτηγά (βλέπε εταιρίες όπως η Waymo LLC της Google, η Tesla, η Lucid, η Pony AΙ κ.ά.), όπου η αυτοματοποίηση της οδήγησης, ειδικά στο κομμάτι της διαδρομής που γίνεται σε αυτοκινητόδρομους και εθνικές οδούς (όπου η κίνηση είναι μικρότερη και οι αλλαγές στην ταχύτητα ή τη λωρίδα είναι λίγες) μπορεί να προσφέρει σημαντική επιτάχυνση των παραδόσεων, αφού το φορτηγό θα μπορεί να κινείται 24/7, με μικρότερη κατανάλωση καυσίμου (λόγω της πιο ομαλής οδήγησης) και μικρότερα ασφαλιστικά κόστη λόγω λιγότερων ατυχημάτων. Το μόνο εμπόδιο που φαίνεται να υπάρχει για την ώρα είναι το κανονιστικό πλαίσιο (π.χ. αν κάποιες πολιτείες των ΗΠΑ αποφασίσουν να νομοθετήσουν εναντίον της πλήρους αυτόνομης οδήγησης τότε πολλές διαπολιτειακές διαδρομές θα πρέπει να αποκλειστούν από τη χρήση τέτοιων φορτηγών), και μια επιφυλακτική στάση των συνδικάτων των οδηγών φορτηγών. Την ίδια στιγμή όμως τονίζεται ότι στις ΗΠΑ (ίσως και αλλού) ο τομέας αυτός φαίνεται να αντιμετωπίζει εδώ και χρόνια δυσκολία στην εξεύρεση οδηγών.
(δ) Υπηρεσίες Υγείας [9][10][11][12][13][14][15]
Ιατρικές υπηρεσίες
Η ανάπτυξη εργαλείων τεχνητής νοημοσύνης στον τομέα της ιατρικής επικεντρώνεται στο κομμάτι της διαγνωστικής και τη σύνθεση εξατομικευμένης αγωγής για κάθε ασθενή. Ο τρόπος λειτουργίας των εργαλείων και εδώ είναι παρόμοιος, και έχει να κάνει με την αναγνώριση μοτίβων μεταξύ εξετάσεων, συνταγογραφήσεων και διαγνώσεων από καταγεγραμμένες περιπτώσεις ασθενών ή έρευνες. Στη συνέχεια, θα μπορεί κάποιος να δώσει ως είσοδο κάποια συμπτώματα ή εξετάσεις, και με βάση αυτά να αναζητηθούν περιπτώσεις με ανάλογα μοτίβα ώστε το σύστημα τεχνητής νοημοσύνης να προτείνει πιθανές αιτιολογίες και πιθανούς τρόπους αντιμετώπισης. Επίσης, θα μπορούσαμε να έχουμε συστήματα τα οποία αναλύουν τις εξετάσεις ενός ασθενή. Για παράδειγμα, εργαλεία τα οποία διαβάζουν ένα ηλεκτροκαρδιογράφημα και παράγουν μια ερμηνεία του, χωρίς την παρουσία ειδικού καρδιολόγου, εντοπίζοντας λεπτομέρειες και ενδείξεις οι οποίες δεν μπορούν να εντοπιστούν εύκολα από το ανθρώπινο μάτι.
Ένα μεγάλο μέρος αυτής της προσπάθειας στηρίζεται στο γεγονός ότι υπάρχει τόση πολύ πληροφορία σε δημοσιευμένα άρθρα που είναι πρακτικά αδύνατο για κάποιον γιατρό να μελετήσει ακόμα και το 1/3 μόνο των πιο σημαντικών δημοσιεύσεων που γίνονται στον τομέα του. Και μάλιστα, όταν το μεγαλύτερο μέρος της πληροφορίας προέρχεται από ιατρικά περιοδικά στα οποία η πρόσβαση δεν είναι δωρεάν. Οπότε, τα εργαλεία τεχνητής νοημοσύνης θα μπορούσαν να συμβάλουν σε σωστότερη και ταχύτερη διάγνωση, καθώς και σε διάγνωση παθήσεων σε πιο αρχικό στάδιο, αυξάνοντας έτσι τις πιθανότητες εφαρμογής μιας κατάλληλης θεραπευτικής μεθόδου, μειώνοντας τα ιατρικά έξοδα και βελτιώνοντας το επίπεδο υγείας των πολιτών. Βέβαια, τα εργαλεία αυτά θα είναι κυρίως συμβουλευτικά και δεν μπορούν να αντικαταστήσουν τον ανθρώπινο παράγοντα, την εκτίμηση που θα κάνει ένας γιατρός και τον συλλογισμό που θα οδηγήσει στην αγωγή που τελικά θα συνταγογραφηθεί.
Θεωρείται σημαντικό να μπορούν εταιρίες και διαγνωστικά κέντρα να εισάγουν εμπιστευτικές ιατρικές πληροφορίες από τη βάση δεδομένων τους στα εργαλεία τεχνητής νοημοσύνης, ώστε να μπορούν να τις χρησιμοποιήσουν σε μελλοντικές διαγνώσεις χωρίς όμως να έχει κανείς άλλος πρόσβαση σε αυτές. Ένα από τα προβλήματα που υπάρχουν για την ώρα είναι ότι, ενώ υπάρχει ήδη μεγάλος όγκος από εξετάσεις (π.χ. ιατρικές εικόνες και γραφήματα), οι περισσότερες δεν έχουν κατάλληλη περιγραφή ώστε να χρησιμοποιηθούν για την εκπαίδευση των εργαλείων τεχνητής νοημοσύνης. Οπότε, η ανάπτυξη και εκπαίδευση τέτοιων εργαλείων είναι χρονοβόρα.
Φαρμακευτική
Αν και γίνονται σημαντικές επενδύσεις για εργαλεία χημείας που θα χρησιμοποιηθούν από φαρμακευτικές εταιρίες, υπάρχει μια αβεβαιότητα σχετικά με το αν τα εργαλεία τεχνητής νοημοσύνης θα μπορούσαν να συμβάλουν σημαντικά στην ανακάλυψη νέων φαρμάκων. Από τη μία, τα εργαλεία που αναπτύσσονται στοχεύουν στην καλύτερη εκτίμηση των ιδιοτήτων που έχουν διάφορα μόρια (συνήθως, μόρια πρωτεϊνών), από τα εκατομμύρια που θα μπορούσαμε να συνθέσουμε, και τα οποία θα μπορούσαν να χρησιμοποιηθούν για τη θεραπεία μιας ασθένειας. Η εκτίμηση αφορά τις ιδιότητες των μορίων αυτών (π.χ. τον βαθμό στον οποίο διαλύονται στο νερό) αλλά και την αλληλεπίδρασή τους με τον ανθρώπινο οργανισμό (π.χ. αν είναι τοξικά, αν φθάνουν ή όχι στον εγκέφαλο κ.λπ.) και ένα μεγάλο μέρος αυτής της εκτίμησης αφορά τη (τρισδιάστατη) μορφή της πρωτεΐνης, η οποία επηρεάζει και την αλληλεπίδρασή της με άλλα μόρια. Αυτή είναι μια εργασία που ταιριάζει αρκετά στα εργαλεία τεχνητής νοημοσύνης που χρησιμοποιούν Noise Diffusion (σύνθεση εικόνας ή βίντεο με βάση μια περιγραφή), με τη διαφορά ότι η περιγραφή εδώ δεν είναι τυπικό κείμενο αλλά περιγραφή της δομής του μορίου πρωτεΐνης.
Φυσικά, απόψεις ότι τα εργαλεία αυτά θα θεραπεύσουν πολύ γρήγορα σχεδόν όλες τις αρρώστιες ανήκουν στη σφαίρα της φαντασίας. Η ανακάλυψη μιας θεραπείας είναι μια χρονοβόρα διαδικασία η οποία δεν ξεκινά καν από τον σχεδιασμό του φαρμάκου. Πρώτα πρέπει να ανακαλυφθεί ο μηχανισμός που προκαλεί την ασθένεια. Στη συνέχεια ακολουθεί η εύρεση του τρόπου με τον οποίο θα αντιμετωπιστεί αυτός ο μηχανισμός. Ακολουθεί ο σχεδιασμός της πρωτεΐνης (φαρμάκου) που θα μπορέσει να φέρει εις πέρας αυτή την εργασία, και έπονται οι απαραίτητες, χρονοβόρες και κοστοβόρες εργαστηριακές δοκιμές και κλινικές μελέτες οι οποίες θα επιβεβαιώσουν ή όχι την αποτελεσματικότητα και την ασφάλεια του φαρμάκου. Αλλά, ακόμα και στη φάση της σχεδίασης του φαρμάκου, η λειτουργία της ανθρώπινης βιολογίας είναι τόσο σύνθετη, που τα εργαλεία τεχνητής νοημοσύνης αναμένεται να δίνουν απλά εκτιμήσεις σχετικά με το πώς θα συμπεριφερθούν τα μόρια του φαρμάκου, βασισμένες σε ομοιότητες με μόρια τα οποία έχουν δοκιμαστεί και με τα οποία το νέο μόριο παρουσιάζει κάποιες δομικές/μορφολογικές ή συμπεριφορικές ομοιότητες. Επιπλέον, σε κάθε περίπτωση θα πρέπει το εργαλείο AI να προσφέρει μια βασική τεκμηρίωση στο γιατί θεωρεί ότι το μόριο θα συμπεριφερθεί με τον τρόπο που περιμένει.
Τέλος, δεν πρέπει να ξεχνάμε ότι πολλοί παράγοντες που δημιουργούν μια πάθηση είναι εξωγενείς (άγχος, κακή διατροφή, μολυσμένος αέρας, κ.λπ.) και η πάθηση δημιουργείται από την αντίδραση του οργανισμού σε αυτούς τους παράγοντες. Αν ένα φάρμακο μπλοκάρει τον μηχανισμό με τον οποίο αντιδρά το σώμα, τότε το σώμα μπορεί να καταφύγει σε άλλο μηχανισμό, δημιουργώντας μια εναλλακτική πάθηση.
(ε) στρατιωτικές εφαρμογές [16][17][18][19][20][21][22]
Σε πάρα πολλές περιπτώσεις, ο όρος τεχνητή νοημοσύνη χρησιμοποιείται καταχρηστικά. Για παράδειγμα, ταυτίζεται η αυτονόμηση ενός drone με τη χρήση συστημάτων τεχνητής νοημοσύνης, ενώ θα μπορούσε να γίνει και χωρίς αυτή (προφανώς, η αυτόνομη λειτουργία του θα έχει μικρότερες δυνατότητες χωρίς τη χρήση AI αλλά αυτό δεν σημαίνει ότι δεν είναι δυνατή). Το πιο σύνηθες είναι ένα drone να χρησιμοποιεί τεχνητή νοημοσύνη σε κάποια από τα υποσυστήματά του, όπως κάποιο υποσύστημα το οποίο επεξεργάζεται τις εικόνες που λαμβάνει από μια κάμερα ώστε να αναγνωρίσει (α) τον τύπο του εδάφους (είναι αυτό που βλέπει μια λίμνη; ένας λόφος; ένα χωράφι με στάχυα;) και (β) αν υπάρχουν εχθρικές εγκαταστάσεις, οχήματα και ανθρώπινο δυναμικό. Το αποτέλεσμα αυτής της ανάλυσης μπορεί χρησιμοποιείται από άλλα υποσυστήματα του drone, τα οποία χρησιμοποιούν κλασσικούς αλγορίθμους (και όχι τεχνητή νοημοσύνη) για να αποφασίσουν αν, για παράδειγμα, το drone θα πρέπει να απομακρυνθεί από την περιοχή, σε ποιον από τους πιθανούς στόχους να δοθεί προτεραιότητα κ.λπ.
Σε γενικές γραμμές, στον τομέα των στρατιωτικών εφαρμογών, η χρήση τεχνητής νοημοσύνης επικεντρώνεται στα εξής:
1. Ανάλυση εικόνας
Την αποτύπωση ενός πεδίου μάχης (γεωγραφία, χαρακώματα, ναρκοθετήσεις) και την αναγνώριση σημείων ενδιαφέροντος (τι είδους εγκαταστάσεις, οχήματα και ανθρώπινο δυναμικό υπάρχουν στο πεδίο, πού είναι τοποθετημένα, αν ανήκουν στον δικό μας στρατό ή του αντιπάλου) μέσω προχωρημένων συστημάτων αναγνώρισης εικόνας που προέρχεται από συνδυασμένες πηγές (ραντάρ, drones, δορυφόρους, κινητά κ.ά.). Η Palantir έχει αναπτύξει ένα παγκόσμιο σύστημα παρακολούθησης το οποίο ονομάζεται MetaConstellation και συνδυάζει πληροφορίες από εκατοντάδες στρατιωτικούς, κυβερνητικούς και εμπορικούς δορυφόρους, το οποίο αναλύει τα δεδομένα αυτόματα και προειδοποιεί για ύποπτες κινήσεις χωρίς να περιμένει την ανθρώπινη πρωτοβουλία.
Τον οπτικό εξοπλισμό του πεζικάριου με σκοπό την αυτόματη αναγνώριση στόχων σε εμβέλεια μεγαλύτερη της ανθρώπινης όρασης.
2. Drone Swarming
Ομάδες από αυτόνομα drones που ανταλλάσσουν πληροφορίες σε πραγματικό χρόνο με σκοπό να δράσουν οργανωμένα για την επίτευξη ενός πολύπλοκου στόχου που μπορεί να αφορά την αναγνώριση στόχων, την εφαρμογή μέτρων ηλεκτρονικού πολέμου κ.ά. Το πλεονέκτημα είναι ότι η συνεργατική αποστολή ομάδας drones προσφέρει ευελιξία στην επίτευξη του στόχου, έτσι ώστε η αποστολή να συνεχιστεί ακόμα και αν κάποια από τα drones παρουσιάσουν βλάβη ή καταρριφθούν.
3. Συστήματα υποστήριξης αποφάσεων (για τη βελτιστοποίηση επιχειρησιακού σχεδιασμού)
Η Palantir αναπτύσσει για τις ΗΠΑ ένα σύστημα προσομοίωσης επιχειρησιακής δράσης το οποίο όμως λειτουργεί με πραγματικά στοιχεία. Έχει πρόσβαση σε πηγές σχετικά με τις στρατιωτικές δυνατότητες του αμερικανικού στρατού (π.χ. πόσα αεροπλάνα υπάρχουν επιχειρησιακά, τι τύπου και πού βρίσκεται το καθένα, πόσοι πύραυλοι Javelin υπάρχουν διαθέσιμοι σε κάθε περιοχή, τι συστήματα ηλεκτρονικού πολέμου μπορούν να ενεργοποιηθούν σε μια περιοχή κ.ο.κ.), σε απόρρητες επιχειρησιακές συνεδριάσεις και στοιχεία σχετικά με επιχειρήσεις του αμερικανικού στρατού (επιχειρησιακούς χάρτες, γεωγραφική κίνηση αεροπλάνων/drones/τανκς που συμμετέχουν σε μια επιχείρηση κ.ά.) και τα χρησιμοποιεί για να εκπαιδευτεί, έτσι ώστε, όταν του παρουσιάσουμε ένα σενάριο/κίνδυνο, να κάνει προτάσεις σχετικά με τις κινήσεις που πρέπει να γίνουν.
Στην ουσία προσπαθεί να συνδυάσει γνώση για το πως ο αμερικανικός στρατός ανταποκρίθηκε σε συγκεκριμένες παλαιότερες καταστάσεις ή σε σενάρια ασκήσεων, ώστε να προτείνει πιθανές μορφές ανταπόκρισης σε μελλοντικές καταστάσεις που μπορεί να προκύψουν. Ο σκοπός είναι η επίσπευση της διαδικασίας λήψης αποφάσεων μειώνοντας τον χρόνο των επιχειρησιακών συνεδριάσεων με το να αφαιρεί το χρονοβόρο κομμάτι της ανάλυσης από τα στελέχη και να περιορίζει τη συνεδρίαση απλά σε συζήτηση επιλογής ενεργειών μεταξύ αυτών που προτείνονται από το σύστημα της Palantir. Αυτό που προβληματίζει κάπως είναι ότι το σύστημα αυτό φαίνεται να έχει τη δυνατότητα ενεργοποίησης διαδικασιών και ενεργειών (ηλεκτρονικά αντίμετρα, αποστολές drones, πυραυλικές επιθέσεις, κ.λπ.), αν και όχι από μόνο του, για την ώρα.
Παρόμοιο είναι και το σύστημα Anticipe που αναπτύσσει η γαλλική Thales για το NATO.
4. Εφοδιαστικές αλυσίδες
Και εδώ υπάρχει ένα σύστημα της Palantir, το Foundry, το οποίο επεξεργάζεται δεδομένα από το πόσες μέρες έχει να κοιμηθεί ένας στρατιώτης του αμερικάνικου στρατού μέχρι τις καθυστερήσεις που μπορεί να υπάρχουν στη συντήρηση κάποιων αεροπλάνων, για να εκτιμήσει πόσο θα είναι το διαθέσιμο αμερικανικό στράτευμα στο κοντινό μέλλον (εκτιμώντας ακόμα και το πόσοι αναμένεται να παραιτηθούν στον επόμενο μήνα ή πόσα αεροπλάνα θα είναι επιχειρησιακά διαθέσιμα ). Και εδώ το μοντέλο στηρίζεται στην εκπαίδευση (τροφοδότηση με δεδομένα και παρατηρήσεις, ώστε να ανιχνευθούν διάφορα μοτίβα που συνδέουν τα δεδομένα εισόδου με τα αποτελέσματα).
(στ) ρομποτική [23][24][25][26][27][28][29][30][31][32][33]
Κατ’ αρχάς, θα πρέπει να ξεκαθαρίσουμε ότι στη βιομηχανία χρησιμοποιούνται ήδη, εδώ και δεκαετίες, πολλών ειδών ρομποτικά συστήματα τα οποία χρησιμοποιούν ελάχιστα έως καθόλου συστήματα τεχνητής νοημοσύνης. Τέτοια ρομποτικά μηχανήματα χρησιμοποιούνται σχεδόν αποκλειστικά σε αυστηρά προκαθορισμένες και επαναλαμβανόμενες εργασίες που εκτελούνται σε συγκεκριμένους χώρους με συγκεκριμένη διαμόρφωση, και γι’ αυτό δεν διαθέτουν ιδιαίτερη προσαρμοστικότητα. Μερικές από τις κατηγορίες αυτών των μηχανημάτων είναι:
Articulated Robots (ρομποτικοί βραχίονες): συνήθως σε βαριές εργασίες όπως η συγκόλληση, η συναρμολόγηση και το πακετάρισμα.  | SCARA robots: για εργασίες τύπου pick&place, πακετάρισμα και σφράγισμα προϊόντων.  |
Cartesian/Linear robots: για εργασίες τύπου 3D-printing και κατασκευαστικές εργασίες τύπου CNC (κοπή, τρύπημα, λύγισμα κ.ά.).  | Delta robots: για εργασίες τύπου pick&place, packaging, ξεσκαρτάρισμα.  |
Collaborative Robots (CoBots): για εργασίες οι οποίες απαιτούν συνεργασία με ανθρώπινους χειριστές. Μπορεί να τα δει κανείς από ιατρικά εργαστήρια μέχρι εργοστάσια κατασκευής αυτοκινήτων. Για να αποφεύγονται οι τραυματισμοί, περιορίζεται κατά πολύ η μέγιστη ροπή που επιτρέπεται να ασκήσουν και η μέγιστη ταχύτητα με την οποία μπορούν να κινηθούν.  | Autonomous Mobile Robots (AMR): μεταφορά και τοποθέτηση προϊόντων (αποθηκευτικοί χώροι).
 |
Τα ρομπότ είναι πιο αποδοτικά από τον άνθρωπο σε απλές, επαναλαμβανόμενες εργασίες οι οποίες δεν απαιτούν ιδιαίτερη σκέψη. Και αυτό συμβαίνει γιατί δεν χρειάζονται μισθό ή ασφαλιστικές εισφορές, δεν αρρωσταίνουν, μπορούν να εργάζονται ασταμάτητα (24/7) και δεν συνδικαλίζονται (άρα δεν ζητάνε αύξηση). Δεν μπορούν όμως να αντικαταστήσουν τον άνθρωπο σε όλες τις εργασίες. Χαρακτηριστικό παράδειγμα ήταν η προσπάθεια του Έλον Μασκ την περίοδο 2016–2018 να αυτοματοποιήσει εντελώς κάποια εργοστάσια παραγωγής της Tesla, η οποία απέτυχε γιατί ο σχεδιασμός και η λειτουργία που απαιτούνταν είχε γίνει τόσο πολύπλοκη που ο ρυθμός παραγωγής είχε πέσει υπερβολικά. Σε γενικές γραμμές όμως, το κλάσμα των ρομποτικών μηχανημάτων που χρησιμοποιείται στη βιομηχανία δια τον αριθμό των εργαζομένων, δηλαδή ο βαθμός αυτοματοποίησης της παραγωγής, βαίνει αυξανόμενο. Προφανώς, το ποσοστό αυτό διαφέρει σημαντικά ανάλογα με το είδος του εργοστασίου (με τα μεγαλύτερα ποσοστά αυτοματοποίησης να παρατηρούνται στην κατασκευή αυτοκινήτων).
Είναι αξιοσημείωτο ότι οι εξελίξεις των τελευταίων ετών στον τομέα της ρομποτικής εισάγουν ένα νέο είδος ρομπότ: τα ανθρωποειδή, τα οποία φιλοδοξούν να αποκτήσουν μεγάλη ευελιξία κινήσεων για εργασίες που δεν περιορίζονται σε συγκεκριμένους χώρους. Κάποια από τα πιο γνωστά μοντέλα τα οποία βρίσκονται υπό ανάπτυξη είναι το Atlas της Boston Dynamics, το Optimus της Tesla, το G1 της Unitree, το Figure 03 της Figure AI και το Protoclone της Clone Robotics. Γενικά, τα ανθρωποειδή ρομπότ χωρίζονται σε δύο κατηγορίες. Αυτά που προορίζονται για γενική χρήση (σε κατοικίες, ξενοδοχεία, καταστήματα) και αυτά που προορίζονται για εξειδικευμένη χρήση. Οι προδιαγραφές τους μπορεί να διαφέρουν ανάλογα με τη χρήση, αλλά είναι ξεκάθαρο πως η πρώτη κατηγορία αποτελεί πολύ μεγαλύτερη τεχνολογική πρόκληση από τη δεύτερη. Για παράδειγμα, τα οικιακά ρομπότ θα πρέπει:
- να είναι ασφαλή στις κινήσεις τους (να μην κάνουν πολύ απότομες κινήσεις, να έχουν περιορισμό στη δύναμη που μπορεί να ασκήσουν, να είναι φτιαγμένα από λιγότερο σκληρά υλικά, να έχουν αισθητήρες πίεσης με μεγαλύτερη ακρίβεια ώστε να
- μην σπάνε τα αντικείμενα που πιάνουν κ.ά.),
- να μην κάνουν πολλή φασαρία,
- θα πρέπει τα πρωτόκολλα απομακρυσμένης πρόσβασης (για έλεγχο, αναβάθμιση κ.λπ.) να μην επιτρέπουν την παρακολούθηση της κατοικίας ή τον απομακρυσμένο έλεγχο των κινήσεων που κάνει το ρομπότ.

Αν και η τεχνολογία που αφορά την κινητικότητα των ανθρωποειδών έχει προχωρήσει αρκετά, τα πολύ ευκίνητα ρομπότ απαιτούν υδραυλικά συστήματα τα οποία είναι πολύπλοκα, ακριβά στην κατασκευή τους, δύσκολα στη συντήρηση, και όταν υπάρχει διαρροή… τα κάνουν χάλια. Γι’ αυτό, φαίνεται πως οι κατασκευαστές έχουν στραφεί στην αποκλειστική χρήση ηλεκτρικών μικροκινητήρων, οι οποίοι όμως προσδίδουν μειωμένες δυνατότητες στην κίνηση. Ακόμα όμως και με αυξημένη κινητικότητα, δεν σημαίνει ότι τα ρομπότ αυτά μπορούν (α) να κατανοήσουν έννοιες, (β) να κάνουν ικανοποιητικά, ή και γρήγορα, καθημερινές εργασίες ή (γ) να συνυπάρξουν χωρίς προβλήματα στο ίδιο περιβάλλον με ανθρώπους. Για κάθε εργασία, χρειάζεται πολλή εκπαίδευση, η οποία, για την ώρα, γίνεται σε περιβάλλον εργαστηρίου και δεν αφορά μόνο την εργασία την ίδια αλλά και το περιβάλλον στο οποίο καλούνται να λειτουργήσουν. Οπότε, φαίνεται πως η ανάπτυξη των ανθρωποειδών ρομπότ προορίζεται κυρίως για εξειδικευμένη χρήση. Τέτοια παραδείγματα χρήσης είναι η φύλαξη περιοχών (ιδιωτικοί χώροι, σύνορα), η αστυνόμευση (περιπολίες, αντιτρομοκρατική), ο στρατός, εργασίες σε επικίνδυνα ή ανθυγιεινά περιβάλλοντα (διαστημικές αποστολές, ραδιενεργές περιοχές, πολύ χαμηλές ή υψηλές θερμοκρασίες) κ.α.
(ζ) συστήματα παρακολούθησης
Τα συστήματα τεχνητής νοημοσύνης δεν θα μπορούσαν να μείνουν εκτός και από συστήματα παρακολούθησης. Ιδιαίτερα όταν μιλάμε για συστήματα που αφορούν κρατικές υπηρεσίες πληροφοριών. Στην ουσία μιλάμε για συστήματα τεχνητής νοημοσύνης που εκπαιδεύονται με πληροφορίες που προέρχονται από πληθώρα πηγών (τηλεφωνικές συνομιλίες, μηνύματα σε social media, emails, πληροφορίες τοποθεσίας από το GPS κινητών τηλεφώνων, ιντερνετική δραστηριότητα κ.ά.), με σκοπό την ανίχνευση ύποπτης δραστηριότητας σχετικά με τρομοκρατικές ενέργειες, κατασκοπία και άλλα εγκλήματα.
(η) κυβερνοασφάλεια
Ο τομέας αυτός περιλαμβάνει την εκπαίδευση συστημάτων τεχνητής νοημοσύνης για την ανίχνευση ύποπτων μορφών δικτυακής κίνησης που θα μπορούσαν να αντιστοιχούν σε ψηφιακές επιθέσεις.
Β2. Γενικότερο αντίκτυπο στην αγορά εργασίας και την οικονομία [34][35][36][37][38][39][40][41][42]
Το αντίκτυπο των εξελίξεων στον τομέα αυτό δεν είναι ξεκάθαρο. Υπάρχουν δύο βασικές απόψεις πάνω στο θέμα:
H πρώτη υποστηρίζεται κυρίως από όσους καθοδηγούν τις εξελίξεις στον τομέα της τεχνητής νοημοσύνης (ερευνητές και διευθυντικά στελέχη εταιριών που αναπτύσσουν τέτοια εργαλεία, καθώς και μεγαλοεπενδυτές του κλάδου), οι οποίοι υποστηρίζουν όχι μόνο ότι τα τεχνολογικά επιτεύγματα είναι πρωτοφανή, αλλά και ότι η εξέλιξη θα είναι ραγδαία τα επόμενα 5–10 χρόνια· σε τέτοιο βαθμό που τα συστήματα τεχνητής νοημοσύνης θα αντικαταστήσουν τον άνθρωπο στα περισσότερα επαγγέλματα. Εξαιτίας αυτού, ευαγγελίζονται ότι θα υπάρχει πληθώρα αγαθών σε πολύ χαμηλή τιμή (λόγω αυτοματοποίησης της παραγωγής), και ότι αυτό θα οδηγήσει σε σημαντική μείωση, αν όχι εξάλειψη, της φτώχειας. Από την άλλη, αυτό σημαίνει ότι θα μείνουν ελάχιστα επαγγέλματα στα οποία ο άνθρωπος θα μπορεί να αποδώσει καλύτερα από ένα ρομπότ ή ένα σύστημα τεχνητής νοημοσύνης. Γι’ αυτόν τον λόγο θα πρέπει να γίνει ένας επανασχεδιασμός του παγκόσμιου οικονομικού συστήματος. Ακόμα και αν θεωρήσουμε ότι αυτή η εκτίμηση είναι υπερβολική, φαίνεται να είναι γενικά αποδεκτό ότι οι νέες τεχνολογίες τεχνητής νοημοσύνης (αυτό που αποκαλούμε 4η βιομηχανική επανάσταση), όπως έκαναν και οι προηγούμενες βιομηχανικές επαναστάσεις, θα οδηγήσουν σε μια περαιτέρω αύξηση του βαθμού αυτοματοποίησης της εργασίας και αντικατάστασης του ανθρώπινου παράγοντα στην παραγωγή. Το πρόβλημα δεν είναι ότι δεν θα υπάρχουν εργασίες για να γίνουν από τον άνθρωπο, αλλά ότι ελάχιστες από αυτές θα αφορούν κάποια βασική ανάγκη· και άρα μικρό μέρος της κατανάλωσης θα κατευθύνεται προς αυτές. Αυτό σημαίνει ότι η φορολογική βάση των κρατών θα δεχτεί σημαντικό πλήγμα (υπερβολική συγκέντρωση πλούτου στους ιδιοκτήτες των εργοστασίων και των συστημάτων αυτοματοποίησης). Έτσι, γίνονται διάφορες συζητήσεις για το πώς θα μπορούσε να αντιμετωπιστεί το πρόβλημα. Μερικές από τις προτάσεις που έχουν γίνει, είναι:
- Εφαρμογή ενός «ρομποτικού φόρου» για τη χρήση ρομποτικών συστημάτων στην παραγωγή (κάποιες μελέτες υποστηρίζουν ότι για τις ΗΠΑ θα πρέπει να είναι στην περιοχή από 1% έως 3.7% —ενώ, αυτή τη στιγμή, για κάθε εργαζόμενο οι εταιρίες πληρώνουν 7.5% φορολογία— ενώ άλλοι λένε ότι θα πρέπει να είναι αρκετά υψηλός για να αντισταθμίσει τις ανισότητες που θα δημιουργηθούν). Τίθενται όμως πολλά ερωτήματα: επί ποιου μισθού θα είναι αυτός ο ρομποτικός φόρος; Επί του ελάχιστου; Πού θα εργαστούν όλοι αυτοί που θα αντικατασταθούν από ρομπότ; Τι εισόδημα θα έχουν όσοι αναγκαστούν να εργαστούν σε άλλες θέσεις οι οποίες προσφέρουν λιγότερο αναγκαίες υπηρεσίες; Ποιο θα είναι το αντίκτυπο της εφαρμογής ενός τέτοιου φόρου στην ανταγωνιστικότητα των εταιριών;
- Αύξηση των θέσεων εργασίας μέσω μείωσης των εβδομαδιαίων ωρών εργασίας (π.χ. πρόταση Berny Sanders) αφού οι υπάλληλοι θα είναι πιο αποδοτικοί.
- Θεσμοθέτηση ενός «παγκόσμιου βασικού εισοδήματος» (Universal Basic Income ή UBI), το οποίο θα διασφαλίζει ένα ελάχιστο εισόδημα σε όλους, ανεξαρτήτως αν εργάζονται ή όχι ή τι εισοδήματα και περιουσία έχουν.
Η δεύτερη άποψη θεωρεί ότι το αντίκτυπο των επιτευγμάτων της τεχνητής νοημοσύνης στην αγορά εργασίας δεν θα είναι τόσο μεγάλο (π.χ. ένα 5% των επαγγελμάτων θα επηρεαστεί σημαντικά) και ότι υπάρχει υπερβολική αισιοδοξία από αυτούς που διαφημίζουν τα σχετικά επιτεύγματα ή επενδύουν σε αυτά. Οι λόγοι είναι πολλοί. Υπάρχουν επαγγέλματα στα οποία η ανθρώπινη επαφή είναι πολύ σημαντική (νοσηλευτές, δάσκαλοι, ψυχολόγοι κ.λπ.) και ο «πελάτης» δεν επιθυμεί την εξάλειψή της. Υπάρχουν επαγγέλματα (π.χ. δικηγόροι, δικαστές, γιατροί, λογιστές) στα οποία η λήψη αποφάσεων είναι τόσο εξατομικευμένη που δύσκολα μπορεί να ληφθεί απλά με χρήση κάποιων μοτίβων που ανακαλύφθηκαν στο υλικό εκπαίδευσης ενός εργαλείου τεχνητής νοημοσύνης. Υπάρχουν επαγγέλματα (π.χ. ηλεκτρολόγοι, υδραυλικοί, αλουμινάδες) τα οποία, από τη μία, απαιτούν μεγάλη τεχνική δεξιότητα και προσαρμοστικότητα τόσο στο περιβάλλον εργασίας όσο και σε απροσδόκητες καταστάσεις (κάτι πολύ δύσκολο για ένα ρομπότ) και, από την άλλη, είναι πολύ δύσκολο να βρεθεί ο όγκος του υλικού εκπαίδευσης που απαιτεί ένα σύστημα τεχνητής νοημοσύνης. Επίσης, σε κάποια από τα επαγγέλματα που προαναφέραμε, καθώς και σε άλλα (π.χ. ανάπτυξη λογισμικού, τραπεζικά συστήματα) δεν μπορούμε να δεχτούμε το γεγονός ότι ένα σύστημα τεχνητής νοημοσύνης μπορεί να δώσει μια απρόβλεπτη και παράλογη ή λάθος έξοδο εξαιτίας παραισθήσεων, γιατί το τίμημα ενός λάθους μπορεί να είναι πολύ μεγάλο. Γι’ αυτό θέλουμε η τελική απόφαση/έλεγχος να γίνεται πάντα από έναν άνθρωπο. Έτσι, η άποψη αυτή υποστηρίζει ότι στα περισσότερα επαγγέλματα, τα εργαλεία τεχνητής νοημοσύνης αναμένεται να παίξουν βοηθητικό ρόλο παρέχοντας ενδείξεις, συμβουλές ή επιχειρήματα στον επαγγελματία. Θα μπορούσε κάποιος να πει ότι η τεχνητή νοημοσύνη αναμένεται να εκτοπίσει από την αγορά εργασίας ένα μέρος των επαγγελματιών που προσφέρουν χαμηλού επιπέδου υπηρεσίες. Αυτούς που δεν προσφέρουν κάτι εξειδικευμένο, το «κάτι παραπάνω», αυτό που δεν μπορεί να προσφέρει το AI. Για παράδειγμα, ένας κτηματομεσίτης που το μόνο που κάνει είναι να μας στέλνει links από διάφορα sites, δεν θα είναι πια χρήσιμος. Εάν όμως έχει πρόσβαση σε ακίνητα τα οποία δεν βρίσκονται σε πλατφόρμες, μας εξηγεί ειδικούς λόγους που δικαιολογούν την αξία του ακινήτου ή μας προτείνει ενδιαφέρουσες ιδέες εκμετάλλευσης που ταιριάζουν στο ακίνητο, τότε θα είναι απαραίτητος. Σε γενικές γραμμές, τα συστήματα Α.Ι θα αντικαταστήσουν εργασίες οι οποίες αποτελούνται από επαναλαμβανόμενα, ανεξάρτητα, σύντομης διάρκειας και σχετικά απλά σε περιγραφή βήματα, στα οποία αν γίνει κάποιο λάθος δεν ήρθε και το τέλος του κόσμου. Όμως, ακόμα και έτσι, κάποιος πρέπει να χτίσει ένα εργαλείο που θα κάνει αυτή τη δουλειά, να το ελέγξει, να το προσαρμόσει στις ανάγκες της κάθε εταιρίας ή επαγγελματία και να το συντηρεί ή να το επιβλέπει για να αναγνωρίζει και να διαχειρίζεται τα λάθη του. Δηλαδή, η απώλεια κάποιων θέσεων εργασίας θα συνοδευτεί, εν μέρει, και από τη δημιουργία κάποιων άλλων.
Αν και οι μεγάλες πολυεθνικές εταιρίες τεχνολογίας φαίνεται να κάνουν μαζικές απολύσεις τα τελευταία 2-3 χρόνια τις οποίες «χρεώνουν» στην ενσωμάτωση συστημάτων τεχνητής νοημοσύνης, τα πράγματα μάλλον δεν είναι όπως φαίνονται. Ένα μέρος των απολύσεων οφείλεται στο γεγονός ότι η παγκόσμια οικονομία δεν βρίσκεται σε καλό δρόμο τα τελευταία χρόνια. Σε πολλές ανεπτυγμένες χώρες ο ρυθμός ανάπτυξης της οικονομίας βρίσκεται σε επιβράδυνση ενώ κάποιες βρίσκονται ήδη σε ύφεση. Επιπλέον, λόγω των υπερβολικών προσδοκιών στην αύξηση της παραγωγικότητας λόγω τεχνητής νοημοσύνης, πολλές εταιρίες έχουν παγώσει τις προσλήψεις. Επίσης, φαίνεται ότι για την ώρα θα υπάρξει μια προσωρινή αλλά σημαντική μείωση των θέσεων εργασίας γιατί, από τη μία, οι υπερβολικές προσδοκίες για τις ικανότητες των συστημάτων τεχνητής νοημοσύνης έχει δημιουργήσει σε κάποιους κλάδους μια παύση προσλήψεων, ιδιαίτερα για χαμηλόβαθμες θέσεις, και, από την άλλη, η προσαρμογή του εκπαιδευτικού συστήματος με τρόπο που να προετοιμάζει τους νέους για τις αλλαγές στην αγορά εργασίας είναι συνήθως αργή και έπεται των εξελίξεων. Σε αυτό συμβάλει και το γεγονός ότι αρκετοί CEO πιέζονται από τα διοικητικά συμβούλια και τους επενδυτές να αποδείξουν ότι μπορούν να αξιοποιήσουν τις καταπληκτικές ικανότητες των συστημάτων Α.Ι (όπως τις ακούνε να διαφημίζονται) για να αυξήσουν τα κέρδη των εταιριών. Αυτό ίσως δημιουργήσει πρόβλημα στο μέλλον γιατί, στις περισσότερες εταιρίες, η γνώση και η εμπειρία μεταδίδεται από τα πάνω προς τα κάτω (από τους πιο έμπειρους στους λιγότερο). Έτσι, όταν έρθει η ώρα να προαχθούν όσοι βρίσκονται στις μεσαίες θέσεις, δεν θα υπάρχει αρκετό προσωπικό στις χαμηλόβαθμες θέσεις για να τους αντικαταστήσει. Όμως, ένα μεγάλο μέρος των μαζικών απολύσεων που βλέπουμε δεν οφείλονται στην αύξηση της παραγωγικότητας αλλά σε μια αντικατάσταση του ανθρώπινου δυναμικού με φθηνότερο. Μάλιστα, σε πολλές περιπτώσεις αυτοί που απολύονται εκπαιδεύουν τους αντικαταστάτες τους πριν αποχωρήσουν. Το 2025, η Amazon όχι μόνο ανακοίνωσε χιλιάδες απολύσεων στις ΗΠΑ, αλλά ήταν και από τις εταιρίες με τις μεγαλύτερες σε αριθμό προσλήψεις εργαζομένων μέσω του προγράμματος H-1B (προσλήψεις εξειδικευμένου προσωπικού από το εξωτερικό με ειδικό καθεστώς μέσω εργολαβίας). Παρόμοια συμβαίνει και με άλλες εταιρίες όπως η Microsoft και η Meta. Η συνήθης δικαιολογία για τις απολύσεις είναι η εφαρμογή συστημάτων Α.Ι και η έλλειψη κατάλληλων προσόντων.
Κοινά αποδεκτή είναι πάντως η πρόβλεψη ότι θα υπάρξει περαιτέρω μηχανοποίηση κάποιων εργασιών (είτε αυτό γίνει μέσω πλήρους αντικατάστασης του ανθρώπου σε κάποια επαγγέλματα, είτε μέσω αυτοματοποίησης ενός μέρους της εργασίας του από εργαλεία τεχνητής νοημοσύνης) και αυτό θα αυξήσει ακόμα περισσότερο την τάση συγκέντρωσης του παγκόσμιου πλούτου σε λίγα χέρια. Τα συστήματα αναδιανομής πλούτου που εφαρμόζονταν μέχρι τώρα στον καπιταλισμό δεν έβαζαν όρια στον πλούτο που μπορεί κανείς να κατέχει. Απλά διασφάλιζαν ότι θα παρέχεται ένα ελάχιστο βιοτικό επίπεδο στους περισσότερους πολίτες, και αυτό κυρίως για να διασφαλίζεται η σταθερότητα του συστήματος για την οποία ανησυχούσαν κυρίως αυτοί που συγκέντρωναν τον πλούτο. Το γεγονός ότι παρά τις προηγούμενες βιομηχανικές επαναστάσεις σήμερα το ελάχιστο βιοτικό επίπεδο είναι αρκετά ανώτερο από αυτό που υπήρχε πριν, δεν σημαίνει ότι αυτό ήταν φυσικό επακόλουθο των βιομηχανικών επαναστάσεων. Το βιοτικό αυτό επίπεδο κατακτήθηκε μέσω πολλών αγώνων, πολλές φορές αιματηρών. Ήταν αποτέλεσμα κοινωνικών διεκδικήσεων των ασθενέστερων οικονομικά στρωμάτων και της εξάπλωσης σοσιαλιστικών ιδεών. Εκτός από κάποιες μικρές ιστορικές περιόδους, η ανισότητα κατά τα τελευταία 200 χρόνια αυξάνεται συνέχεια. Το τι θα συμβεί με την τρέχουσα βιομηχανική επανάσταση αναμένεται να φανεί στα επόμενα χρόνια.
Η ιδέα του Παγκόσμιου Βασικού Εισοδήματος (Universal Basic Income) [43][44][45][46][47][48][49][50][51]
Η βασική ιδέα στο «παγκόσμιο βασικό εισόδημα» (UBI) είναι ότι όλοι οι πολίτες της χώρας (άνω των 18), χωρίς εξαιρέσεις, θα λαμβάνουν ένα ελάχιστο μηνιαίο εισόδημα, το οποίο θα είναι το ίδιο για όλους. Η συνήθης πρόταση είναι ότι τα χρήματα θα προέλθουν από επιπλέον φορολόγηση των μεσαίων και μεγάλων εισοδημάτων. Το UBI παρουσιάζεται ως μια νέα μορφή συστήματος αναδιανομής του πλούτου με αλτρουιστικό σκοπό και στόχο να αντικαταστήσει ένα κομμάτι του συστήματος κοινωνικής πρόνοιας. Το επιχείρημα είναι ότι το τρέχον σύστημα κοινωνικής πρόνοιας είναι δυσκίνητο, άδικο (εξαιρεί ανθρώπους που δεν θα έπρεπε λόγω των πολύπλοκων κανόνων) και σε πολλές περιπτώσεις διεφθαρμένο. Οπότε, είναι καλύτερο η όποια οικονομική στήριξη να πηγαίνει κατευθείαν στον λογαριασμό κάθε πολίτη και όχι να γίνεται επιλογή των δικαιούχων μέσω κρατικών υπηρεσιών. Με άλλα λόγια, αν και η θεσμοθέτησή του θα ορίζεται από το Κράτος, η λειτουργία του θα παρακάμπτει οποιαδήποτε κριτήρια και θα υλοποιεί την κοινωνική-οικονομική στήριξη με απευθείας σύνδεση των φορολογούμενων (κυρίως μεγάλες εταιρίες, με βάση την παρατηρούμενη τάση συγκέντρωσης του πλούτου) με τους αποδέκτες (πολίτες).
Υπάρχει βέβαια και η οπτική γωνία της Silicon Valley, για την οποία το επιχείρημα είναι ότι το UBI θα έρθει ως αποτέλεσμα της αντικατάστασης ενός μεγάλου αριθμού επαγγελμάτων από αυτοματοποιημένες εργασίες. Στην ουσία θα είναι μια οικονομική απολαβή που θα δίνεται για να αποδεχτούν, όσοι χάσουν την εργασία τους, έναν κόσμο όπου οι περισσότερες εργασίες θα είναι αυτοματοποιημένες. Επειδή αυτό θα ήταν κάτι προβληματικό σε επίπεδο αποδοχής, το UBI παρουσιάζεται και από άλλες οπτικές γωνίες. Όπως ότι τα κέρδη των μεγάλων εταιριών οφείλονται σε μια διαγενεακή προσπάθεια και άρα ένα σημαντικό μέρος τους θα πρέπει να διατεθεί για το κοινό καλό. Παράλληλα, γίνεται σημαντική προσπάθεια να δικαιολογηθεί το γιατί αυτή η εκτεταμένη αυτοματοποίηση είναι αναγκαία (π.χ. δημογραφικό πρόβλημα, εξερεύνηση του διαστήματος, εξάλειψη της φτώχειας μέσω της υπεραφθονίας κ.ά.).
Να τονίσουμε εδώ ότι η ιδέα της αντικατάστασης της εργασίας με ένα εξασφαλισμένο εισόδημα, όταν και όπου χρησιμοποιείται, φαίνεται να είναι ιδιαίτερα προβληματική. Η εργασία δεν είναι μόνο ένα μέσο οικονομικής απολαβής. Δίνει νόημα στον άνθρωπο. Mας κάνει να αισθανόμαστε ότι συμβάλλουμε στη λειτουργία της κοινότητας/κοινωνίας στην οποία συμμετέχουμε. Mας κάνει να εκτιμάμε αυτά που έχουμε γιατί αποκτήθηκαν με κόπο, και να είμαστε σώφρονες στη διαχείρισή τους. Μας κάνει να αισθανόμαστε ότι είμαστε άξιοι αυτών που κατέχουμε και ότι δεν μας “κάνουν χάρη” που μας συντηρούνε. Σε πολλά επαγγέλματα, μας δίνει τη χαρά της δημιουργίας. Η λειτουργία της και η συνεισφορά της στην ψυχοσωματική υγεία και διαμόρφωση του ατόμου δεν μπορούν να αντικατασταθούν απλά με ένα επίδομα. Γι’ αυτό και το δικαίωμα στην εργασία αποτελεί ένα από τα θεμελιώδη ανθρώπινα δικαιώματα. Για να ικανοποιηθεί όμως θα πρέπει να υπάρχουν ευκαιρίες για εργασία, και μάλιστα σε αρκετούς τομείς, ώστε να ικανοποιηθεί και η ελευθερία στην επιλογή του επαγγέλματος. Αυτό πρέπει να τονιστεί, γιατί πολλοί υποστηρίζουν ότι το UBI δεν έχει σκοπό να καταργήσει την εργασία, η οποία είναι πολύ σημαντική για τον άνθρωπο. Απλά θα πρέπει να δοθεί από την κοινωνία μεγαλύτερη αξία σε είδη εργασίας τα οποία μέχρι τώρα θεωρούνταν υποτιμημένα, όπως η ανατροφή των παιδιών και οι δουλειές του σπιτιού, η καλλιτεχνική δημιουργία, η φροντίδα άλλων ανθρώπων κ.λπ.
Η ιδέα του UBI εγείρει πολλά ερωτήματα σχετικά με το πόσο λειτουργική θα ήταν μια εφαρμογή του. Ένα από αυτά είναι το τι θα γίνει αν πολλοί από αυτούς που θα λαμβάνουν το UBI στραφούν απλά προς μια παρασιτική επιβίωση (τεμπελιά) ή και αυτοκαταστροφικές συμπεριφορές (π.χ. ποτό, ναρκωτικά κ.λπ.) αντί να ασχοληθούν με άλλων ειδών εργασίες, οι οποίες πιθανόν να θεωρηθούν υποτιμημένες απέναντι στις εργασίες υψηλής εξειδίκευσης που η τεχνητή νοημοσύνη δεν μπορεί να αντικαταστήσει. Κάποιοι υποστηρίζουν ότι αυτό δεν θα γίνει γιατί:
(α) οι άνθρωποι θέλουν να νοηματοδοτούν τη ζωή τους και η εργασία είναι απαραίτητη γι’ αυτό.
(β) κάποιοι δεν εργάζονταν έτσι κι αλλιώς, και αντί να ανησυχούν γι’ αυτό θα μπορούν να ασχοληθούν με κάτι το οποίο θα προσφέρει στην κοινότητα δωρεάν (εθελοντική εργασία).
(γ) η τάση για την κοινωνική αποδοχή κάποιου ως χρήσιμου πολίτη και όχι ως κάποιου που ζει εις βάρος των άλλων θα ωθήσει τους περισσότερους προς την εργασία.
(δ) το UBI θα είναι κάτω από το όριο της φτώχειας ώστε να μην αντικαθιστά ένα, έστω και μικρό, εργασιακό εισόδημα.
Όσον αφορά τα πλεονεκτήματα του UBI, υποστηρίζεται ότι αυτό θα περιορίσει το κόστος κάποιων βασικών υπηρεσιών, όπως οι υπηρεσίες υγείας, γιατί οι πολίτες χαμηλών εισοδημάτων θα έχουν καλύτερη διατροφή, λιγότερο άγχος για την απόκτηση των βασικών αγαθών και θα είναι κάπως πιο ξεκούραστοι γιατί, θα χρειάζεται να δουλεύουν λιγότερες υπερωρίες. Επίσης, θα δώσει σε πολλούς νέους την οικονομική δυνατότητα να σπουδάσουν, και έτσι να καλύψουν τις θέσεις υψηλών προσόντων που θα απαιτήσει η νέα αγορά εργασίας. Ένα αντεπιχείρημα είναι ότι το UBI θα οδηγήσει πολλούς χαμηλά αμειβόμενους να σταματήσουν την εργασία ή να εργάζονται λιγότερες ώρες. Αυτό θα ήταν καταστροφικό για την παραγωγή, εκτός… αν η παραγωγή τους αντικαταστήσει με αυτοματοποιημένα συστήματα. Κάτι που, με τη σειρά του, μπορεί να φέρει τα εξής προβλήματα:
(α) το κόστος του παραγωγού δεν εξαρτάται πια από τον πληθωρισμό (το κόστος ζωής) αλλά από το πόσο οι μεγάλες εταιρίες θα αποφασίσουν να τιμολογήσουν την αγορά, τη συντήρηση και την επιδιόρθωση ενός ρομποτικού συστήματος. Κάτι το οποίο μπορεί να μεταβληθεί απότομα και δεν είναι τόσο ελεγχόμενο όσο ο πληθωρισμός.
(β) ενώ ο (πρώην) εργαζόμενος θα βγάζει τα ίδια (ή σχεδόν τα ίδια), οι μεγάλες εταιρίες θα αυξάνουν τα έσοδά τους για κάθε εργαζόμενο που αντικαθιστούν με ρομποτικό σύστημα. Αυτό θα δημιουργήσει πιο μεγάλες ανισότητες.
(γ) θα υπάρξει μεγάλο αντίκτυπο στο ήθος και την παιδεία των πρώην εργαζόμενων, οι οποίοι πλέον θα απολαμβάνουν τα βασικά χωρίς να έχουν μοχθήσει.
Μία απάντηση είναι ότι, έχοντας εξασφαλισμένα μέσω του UBI τα πολύ βασικά (το UBI δεν θα προσμετράται στην φορολόγηση), το εισόδημα από εργασία θα προσφέρει πολλές μεγαλύτερες ανέσεις από ό,τι πριν, και αυτό θα δίνει μεγαλύτερο κίνητρο σε κάποιον για να δουλέψει. Από την άλλη, η χρηματοδότηση του UBI θα προέλθει από αύξηση της φορολογίας. Δηλαδή, με τον ίδιο μισθό κάποιος θα βγάζει λιγότερα από ότι πριν. Αυτό είναι αντικίνητρο για την εργασία. Επίσης, είναι πολύ πιθανό, παρά τις όποιες ρητορικές διασφαλίσεις, ότι η εφαρμογή ενός UBI θα οδηγήσει σε άλλες κοινωνικές περικοπές επιδομάτων, φορολογικών εκπτώσεων κ.λπ., γιατί το ύψος της αύξησης στην φορολόγηση που απαιτεί το UBI είναι αρκετά υψηλό.
Οι δοκιμές του UBI που γίνονται σε διάφορες περιοχές και κράτη είναι περιορισμένης διάρκειας και δεν είναι πολύ αντικειμενικές. Αυτό συμβαίνει γιατί οι συμμετέχοντες θα πρέπει να επιστρέψουν στην εργασία τους μετά το τέλος του πειράματος. Έτσι, οι αποφάσεις που λαμβάνονται (π.χ. για το αν θα συνεχίσουν να δουλεύουν όσο λαμβάνουν το UBI) δεν είναι ενδεικτικές του τι θα γινόταν σε μια μόνιμη εφαρμογή του UBI. Επίσης, σε κάποιες από αυτές δεν αυξάνεται καν η φορολογία όσων εργάζονται, κάτι το οποίο δεν συνάδει με το πως υποτίθεται ότι θα χρηματοδοτηθεί το UBI στην πράξη. Τέλος, τα πειράματα αυτά σπάνια λαμβάνουν υπόψη τον αυξημένο πληθωρισμό με τον οποίο θα συνοδευτεί το αυξημένο βιοτικό επίπεδο των ανθρώπων ή το πως η εφαρμογή ενός UBI θα επηρέαζε τους προσφερόμενους μισθούς στην αγορά εργασίας. Κατά συνέπεια, η εξαγωγή ενός καθαρού συμπεράσματος είναι πολύ δύσκολη.
Αξίζει να προσέξουμε ότι η συζήτηση για το UBI έρχεται στο προσκήνιο κυρίως από κύκλους των πολιτικο-οικονομικών ελίτ, και όχι από σοσιαλιστικά πολιτικά κόμματα ή «δεξαμενές σκέψης». Ακόμα, δεν είναι τυχαίο ότι οι πολιτικές που εφαρμόστηκαν κατά τη διάρκεια των lockdowns για τον covid χρησιμοποιήθηκαν για τη μελέτη του κατά πόσο θα ήταν αποδεκτή η εφαρμογή του UBI και πώς αυτή θα επηρέαζε μια κοινωνία.
Β3. Ζητήματα κοινωνικού προβληματισμού σχετικά με τις τεχνολογίες AI
1. Λογοκλοπή [52][53]
Οι νέες τεχνολογίες που βασίζονται στα νευρωνικά δίκτυα και ιδιαίτερα τα LLMs, τα οποία «καταπίνουν» λαίμαργα τόνους πληροφορίας, έχουν εγείρει κάποια θέματα σχετικά με τη λογοκλοπή. Λογοκλοπή είναι η παράνομη οικειοποίηση της γλώσσας, των σκέψεων, των ιδεών, ή εκφράσεων ενός άλλου συγγραφέα και της εκπροσώπησης αυτών ως αρχικής εργασίας κάποιου. Η έννοια της λογοκλοπής περιέχει, ως ένα βαθμό, ασαφείς ορισμούς και ασαφείς κανόνες. Αν και πολλές φορές η λογοκλοπή δεν είναι έγκλημα καθαυτή, στην ακαδημαϊκή κοινότητα και τη βιομηχανία, είναι μια σοβαρή και ανήθικη πράξη, και περιπτώσεις λογοκλοπής μπορεί να αποτελέσουν παραβίαση πνευματικών δικαιωμάτων.
Είναι γνωστό ότι τα LLMs αντιγράφουν στις απαντήσεις τους κείμενα αυτούσια, ή περίπου αυτούσια, τα οποία έχουν βρει στο διαδίκτυο ή χρησιμοποιήθηκαν για την εκπαίδευσή τους. Αυτό συμβαίνει σε σημαντικό βαθμό (στο ChatGPT 3.5 η λογοκλοπή έφτανε το 46%, ενώ στο ChatGPT 4 έχει μειωθεί αλλά συνεχίζει να συμβαίνει σε σημαντικό βαθμό). Και, σαν να μην έφτανε αυτό, συχνά δεν περιέχουν παραπομπές στις πηγές από τις οποίες πήραν το κείμενο ή χρησιμοποιούν λανθασμένες παραπομπές. Αυτό είναι ένα πρόβλημα το οποίο δεν μπορεί να αντιμετωπιστεί εύκολα γιατί οι κανόνες που πλαισιώνουν το αδίκημα της λογοκλοπής είναι πολύπλοκοι και περιέχουν στοιχεία υποκειμενικότητας ή στοιχεία τα οποία δεν μπορούν να εκτιμηθούν από το LLM, όπως πόσο σύνηθες είναι το κείμενο που αντιγράφουν, πώς θα χρησιμοποιηθεί, σε τι είδους εργασία θα ενσωματωθεί κ.λπ. Επίσης, για σημαντικό τμήμα της πληροφορίας, το LLM δεν μπορεί να εντοπίσει από που αποκτήθηκε, αλλά, ακόμα και αν μπορούσε, του είναι δύσκολο να διακρίνει αν κάποια από τις πηγές είναι η αυθεντική ή δευτερεύουσα (δηλαδή, αν η πηγή Β το πήρε από την πηγή Α ή αν η Β ήταν αυτή που έχει την πνευματική ιδιοκτησία του κειμένου ή της πληροφορίας). Δεδομένου ότι ακόμα και ένας άνθρωπος μπορεί να κάνει λάθη σε τέτοια θέματα, ένα LLM αναμένεται να έχει ακόμα χειρότερη απόδοση.
Τίθεται λοιπόν το ερώτημα αν αυτό που γίνεται είναι νόμιμο ή όντως λαμβάνει χώρα το αδίκημα της λογοκλοπής. Στις ΗΠΑ υπάρχουν ήδη σχετικές αποφάσεις δικαστηρίων τουλάχιστον για δύο περιπτώσεις, σύμφωνα με τις οποίες θα λέγαμε ότι η μετασχηματισμένη αναπαραγωγή περιεχομένου που προστατεύεται από πνευματική ιδιοκτησία σε γενικές γραμμές είναι επιτρεπτή. Το σκεπτικό είναι πως η χρήση ενός βιβλίου από ένα LLM δεν διαφέρει πολύ από έναν άνθρωπο που έχει διαβάσει ένα αντίτυπο αυτού του βιβλίου, το έχει κάνει κτήμα του και στη συνέχεια προσπαθεί να δημιουργήσει νέα έργα χρησιμοποιώντας, μεταξύ άλλων, διάφορα εκφραστικά στοιχεία τα οποία έχει μάθει από αυτό το βιβλίο. Όμως, η τελική απόφαση μπορεί να διαφέρει ανά περίπτωση με βάση κάποιες παραμέτρους, όπως:
(α) σε τι βαθμό το περιεχόμενο έχει μετασχηματιστεί από το LLM,
(β) αν αποδεικνύεται ότι η χρήση του περιεχομένου από το LLM είχε αντίκτυπο στην εμπορικότητα του βιβλίου και τα κέρδη από αυτό,
(γ) κατά πόσο το αντίτυπο του βιβλίου αποκτήθηκε νόμιμα και χρησιμοποιήθηκε μόνο για εκπαίδευση ή έχει αποθηκευτεί κάπου.
2. Πλαστοπροσωπία [54][55][56]
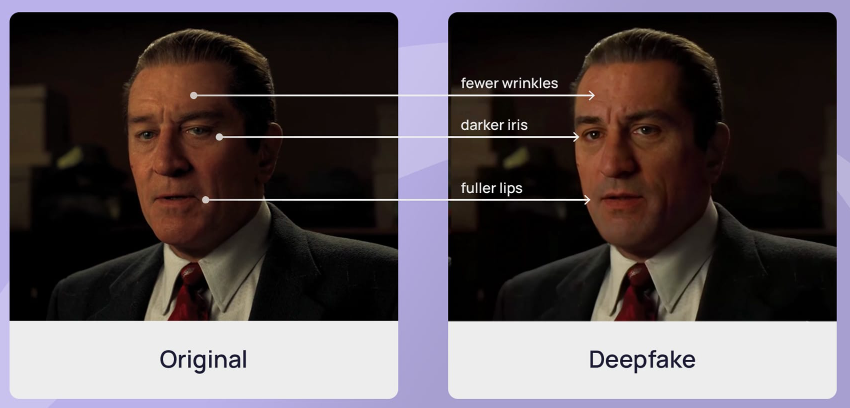
Μέχρι σήμερα οι προσπάθειες πλαστοπροσωπίας περιορίζονταν σε κάποια email προερχόμενα από ύποπτες διευθύνσεις, με ορθογραφικά ή εκφραστικά λάθη και εξωπραγματικά σενάρια τα οποία δεν έπειθαν κανέναν. Ίσως και κάποιες τηλεφωνικές κλήσεις αγνώστων, από αριθμούς με απόκρυψη. Τώρα, με τις δυνατότητες της τεχνητής νοημοσύνης, αυξάνεται σε μεγάλο βαθμό η δυνατότητα πλαστοπροσωπίας, με την παραγωγή ψεύτικων εικόνων, ηχητικών και βίντεο, τα οποία θα είναι πολύ δύσκολο να καταλάβουμε αν είναι αληθινά ή όχι. Είναι χαρακτηριστικό ότι κάποιος μπορεί να κλωνοποιήσει τη φωνή μας αν έχει ακόμα και τρία δευτερόλεπτα ηχητικό από αυτή (συνήθως απαιτούνται 10–30 δευτερόλεπτα για καλή ποιότητα), και να τη χρησιμοποιήσει για να ξεγελάσει κάποιο γνωστό μας πρόσωπο ή κάποιον εμπορικό/επαγγελματικό συνεργάτη μας. Το ίδιο μπορεί να γίνει και με βίντεο, αλλά απαιτείται περισσότερη πληροφορία για να είναι αληθοφανές. Κάτι που, φυσικά, δεν είναι δύσκολο να βρεθεί για πρόσωπα που έχουν δημόσια παρουσία. Επίσης, μέσω της τεχνητής νοημοσύνης μπορούν πιο εύκολα να συγκεντρωθούν προσωπικές πληροφορίες για εμάς, ώστε η προσπάθεια πλαστοπροσωπίας να είναι πολύ πιο αληθοφανής. Έχουν υπάρξει περιπτώσεις όπου άτομα που συμμετείχαν σε μια βιντεοκλήση δεν μπόρεσαν να καταλάβουν ότι οι υπόλοιποι συμμετέχοντες δεν ήταν στην πραγματικότητα εκεί.
Κάποια συχνά σενάρια στα οποία χρησιμοποιείται στην πράξη η πλαστοπροσωπία είναι:
- κάποιο συγγενικό μας πρόσωπο να μας καλέσει για να μας ζητήσει επειγόντος χρήματα ή κάποια ευαίσθητη πληροφορία
- να μας καλέσουν από κάποια τράπεζα ή κάποια δημόσια υπηρεσία (π.χ. αστυνομικό τμήμα, εφορία) για να ζητήσουν κάποια ευαίσθητη πληροφορία ή κάποια μετακίνηση χρημάτων
- να καλέσουν στο σπίτι όταν λείπουμε και να μιλήσουν στα παιδιά μας προσποιούμενοι ότι είμαστε εμείς. Τα παιδιά, που είναι λιγότερο υποψιασμένα, μπορεί να δώσουν πληροφορίες για εμάς, για το πού βρισκόμαστε ή ποιες ώρες λείπουμε, για το εσωτερικό του σπιτιού ή ακόμα και να τα προτρέψουν να βγάλουν κάτι από το σπίτι ή να πάνε τα ίδια κάπου εκτός σπιτιού.
Δυστυχώς, δεν είναι εύκολο να αντιληφθούμε την απάτη σε μια τέτοια κατάσταση. Κάποιες ενέργειες που μπορούμε να κάνουμε όμως για αποφύγουμε την απάτη είναι:
- να καλέσουμε πίσω αυτόν που μας κάλεσε, αν γίνεται, μέσω ενός δημόσια γνωστού τηλεφώνου (αν είναι ιδιωτική ή δημόσια υπηρεσία)
- να επιβεβαιώσουμε μια κατάσταση μέσω τρίτου
- να βεβαιωθούμε ότι τα μέλη της οικογένειάς μας γνωρίζουν μια «μυστική» λέξη/φράση που μπορούν να μας της ζητήσουν για να επιβεβαιώσουν ότι είμαστε εμείς που τους μιλάμε στο τηλέφωνο ή που τους ζητάμε να ανοίξουν την πόρτα
- να αποφεύγουμε να δίνουμε ευαίσθητες πληροφορίες μέσω τηλεφώνου ακόμα και αν μας τις ζητάει γνωστό άτομο. Θα μπορούσαμε να του τις στείλουμε με κάποιον άλλο τρόπο (π.χ. μέσω SMS, εφόσον γνωρίζουμε το τηλέφωνό του εκ των προτέρων).
Επίσης, δεν είναι σπάνιο να χρησιμοποιούνται και βίντεο με πλαστοπροσωπίες (deepfakes) δημοσίων προσώπων (π.χ. πολιτικών) ή εταιριών για να παραπλανηθεί ο κόσμος και να επηρεαστούν οι πολιτικές του αντιλήψεις ή οι καταναλωτικές του επιλογές.
Πώς να αποφύγουμε ψεύτικα βίντεο (deepfakes):
- βλέπουμε στα σχόλια αν υπάρχουν άλλοι που θεωρούν ότι το βίντεο είναι ψεύτικο
- αναζητούμε το βίντεο σε άλλες πηγές και ιστοσελίδες που ξέρουμε ότι είναι πιο αξιόπιστες
- ψάχνουμε τα social media των προσώπων που πρωταγωνιστούν στο βίντεο
- αναζητούμε παράξενα σημεία στο βίντεο
- δεν βιαζόμαστε να βγάλουμε συμπεράσματα, αν αυτό που βλέπουμε στο βίντεο μας φαίνεται απίθανο να έχει συμβεί.
Επιπλέον, χρειάζεται να είμαστε προσεκτικοί γιατί υπάρχουν κάποιες κακόβουλες online υπηρεσίες, οι οποίες, με την υπόσχεση ανώνυμης πρόσβασης σε κάποιο γνωστό chatbot, αποκτούν προσωπικές μας πληροφορίες που το chatbot κατέχει. Επίσης, υπάρχουν κακόβουλες ιστοσελίδες οι οποίες περιέχουν εντολές προς τα chatbot που τα κάνουν να παράγουν μια απάντηση η οποία μας θέτει σε κίνδυνο, όταν ζητήσουμε από το chatbot να χρησιμοποιήσει περιεχόμενο από τη συγκεκριμένη ιστοσελίδα.
Τέλος, καλό είναι να έχουμε υπόψη μας ότι τα generative AIs μπορούν να στήσουν μέσα σε λίγα λεπτά ένα αντίγραφο μιας ιστοσελίδας, συμπεριλαμβανομένων και ψεύτικων κριτικών από χρήστες ή μιας υπηρεσίας live chat. Γι’ αυτό θα πρέπει να δίνουμε ιδιαίτερη προσοχή στο URL του browser όταν επισκεπτόμαστε μια ευαίσθητη ιστοσελίδα (π.χ. το web banking της τράπεζάς μας). Το ίδιο εύκολο είναι να στηθούν και ψεύτικα προφίλ σε social media ή ψεύτικοι δημοσιογράφοι που παρουσιάζουν ειδήσεις (ελαφρώς τροποποιημένες) τις οποίες θα αντιγράφουν από άλλες ιστοσελίδες.
3. Λογοκρισία και διαμόρφωση απόψεων [57][58][59][60][61][62]
Η ανάσυρση και σύνθεση της πληροφορίας από τα LLMs έχει κανόνες. Το LLM δεν αφήνεται να απαντήσει μόνο με βάση την πληροφορία με την οποία εκπαιδεύτηκε, αλλά γίνονται παρεμβάσεις τόσο κατά την εκπαίδευση όσο και κατά την κανονική λειτουργία του, με σκοπό την ευθυγράμμιση των απαντήσεων με τους σκοπούς και τις αξίες του δημιουργού, τις απαιτήσεις της αγοράς καθώς και τη νομοθεσία. Έτσι, ενώ υπό κανονικές συνθήκες οι απαντήσεις ενός LLM θα έπρεπε να επηρεάζονται σχεδόν αποκλειστικά από το πόσο δημοφιλής είναι μία άποψη, και άρα πόσο συχνά μπορεί να τη βρει κανείς σε ιστοσελίδες, άρθρα, βιβλία κ.λπ. (μια άποψη που εμφανίζεται πάρα πολύ συχνά στο υλικό θα έχει προτεραιότητα και θεωρείται πιο αξιόπιστη από κάποια άποψη που εμφανίζεται ελάχιστες φορές), οι απαντήσεις επηρεάζονται και από τις εξής παρεμβάσεις:
(α) αποκλεισμός από την εκπαίδευση περιεχομένου το οποίο θεωρείται βλαπτικό για τη λειτουργία του LLM
Τέτοιο υλικό μπορεί να είναι αυτό που περιέχει ρατσιστική γλώσσα, πορνογραφικό περιεχόμενο, περιεχόμενο που προστατεύεται από δικαιώματα πνευματικής ιδιοκτησίας κ.λπ. Βέβαια, η διάκριση αυτή δεν είναι εύκολο να γίνει αυτοματοποιημένα. Για παράδειγμα, θα έπρεπε το έργο «Ο Αγών μου» του Χίτλερ να αποκλειστεί από την εκπαίδευση του LLM ώστε να αποφύγουμε την αναπαραγωγή ναζιστικών αντιλήψεων; Η όχι, γιατί θέλουμε να μπορεί να απαντήσει σε ερωτήσεις που αφορούν είτε το ίδιο το βιβλίο, είτε τον Χίτλερ; Ένα άλλο παράδειγμα είναι τα κινέζικα LLMs, τα οποία αποκλείουν κάθε πηγή πληροφόρησης σχετικά με την πλατεία Τιεν Αν Μεν (και τα αιματηρά γεγονότα του 1989), εκτός κι αν η πηγή είναι κυβερνητική. Οι ακριβείς κανόνες, με βάση τους οποίους κάθε δημιουργός ενός LLM αποφασίζει αν κάποιο υλικό θα πρέπει να αποκλειστεί ή όχι, δεν δημοσιοποιούνται.
(β) βαθμολόγηση της αξιοπιστίας κάθε πηγής
Οι δημιουργοί του LLM συχνά το ρυθμίζουν να θεωρεί ότι κάποιες πηγές είναι πιο αξιόπιστες από άλλες (π.χ. κυβερνητικές ιστοσελίδες, ιστοσελίδες συγκεκριμένων διεθνών οργανισμών, συγκεκριμένοι λογαριασμοί κοινωνικής δικτύωσης κ.λπ.), με αποτέλεσμα το υλικό που το LLM βρίσκει εκεί να επηρεάζει τις απαντήσεις του πιο έντονα από το υπόλοιπο υλικό.
(γ) εισαγωγή φίλτρων από τους δημιουργούς του LLM
Τα φίλτρα αυτά είναι δύο ειδών. Υπάρχουν φίλτρα ερωτήσεων τα οποία δεν επιτρέπουν στον χρήστη να κάνει συγκεκριμένες ερωτήσεις (δεν αφήνουν καν το LLM να επιχειρήσει να συνθέσει μια απάντηση) και υπάρχουν φίλτρα απαντήσεων τα οποία αποτρέπουν το LLM να δώσει στον χρήστη κάποιες απαντήσεις (το LLM θα συνθέσει μια απάντηση την οποία μπορεί το φίλτρο να κόψει επειδή τη θεώρησε ακατάλληλη). Το σκεπτικό είναι να αποτραπούν απαντήσεις οι οποίες μπορεί να είναι βλαπτικές για τον χρήστη και την κοινωνία ή να προκαλέσουν προβλήματα στην εταιρία στην οποία ανήκει το LLM. Για παράδειγμα, οδηγίες για την κατασκευή βιολογικών όπλων ή του πώς να χακάρουμε μια ιστοσελίδα θα πρέπει να εμποδίζονται. Το ίδιο και για κείμενα τα οποία μπορεί να εκφράζουν μίσος, ή να περιέχουν απειλές ή παράνομο περιεχόμενο. Το φίλτρο απάντησης είναι πιο σημαντικό, γιατί πολλές φορές ο χρήστης μπορεί να βρει τρόπο να ξεγελάσει το LLM και έτσι αυτό να μην καταλάβει από την αρχή τι είναι αυτό που προσπαθεί να μάθει ο χρήστης. Για παράδειγμα, μπορεί ένα φίλτρο ερώτησης να «κόψει» μια ερώτηση για το πως μπορούμε να διαρρήξουμε ένα σπίτι, αλλά να μην κόψει μια ερώτηση για το πως ένα ιδιοκτήτης κατοικίας θα μπορούσε να προστατευθεί από επίδοξους διαρρήκτες (η οποία πιθανόν να αναλύει και τεχνικές με τις οποίες κάποιος κάνει μια διάρρηξη). Η λογοκρισία μπορεί να εφαρμόζεται και σε μία ολόκληρη θεματική περιοχή αντί για συγκεκριμένα ερωτήματα. Όπως είναι αναμενόμενο, τέτοιου είδους φίλτρα μπορεί να μπλοκάρουν, ως παράπλευρη λειτουργία, και ερωτήματα που δεν θα έπρεπε να μπλοκαριστούν.
(δ) ρυθμίσεις οι οποίες, για συγκεκριμένα θέματα, δεν μπλοκάρουν τις απαντήσεις αλλά καθοδηγούν την απάντηση προς συγκεκριμένες κατευθύνσεις ανεξαρτήτως του υλικού εκπαίδευσης.
Δεδομένου ότι η επανεκπαίδευση των LLMs είναι και χρονοβόρα και κοστοβόρα, η ευελιξία που πολλές φορές απαιτείται από τα LLMs (λόγω αλλαγής της νομοθεσίας, κυβερνητικών πιέσεων, κοινωνικής κατακραυγής και άλλων δυναμικών παραγόντων) επιτυγχάνεται κυρίως μέσω παρεμβάσεων τύπου (γ) και (δ). Βέβαια, αυτό δεν σημαίνει ότι τέτοιου είδους παρεμβάσεις είναι εύκολες στην υλοποίηση. Επίσης, δημιουργεί προβληματισμό το ότι περιεχόμενο που παράγεται από τα τωρινά LLMs πρόκειται να χρησιμοποιηθεί για την εκπαίδευση μελλοντικών LLMs, λόγω ευκολίας. Έτσι, προκαταλήψεις και εκφραστικές τάσεις που εισάγονται τώρα μέσω των παραπάνω τεχνικών λογοκρισίας θα είναι πιο δύσκολο να αφαιρεθούν από τα LLMs στο μέλλον.
Όλες αυτές οι επεμβάσεις σημαίνουν ότι, εκ των πραγμάτων, το LLM είναι προκατειλημμένο με βάση (α) τις αντιλήψεις και πεποιθήσεις των δημιουργών του, (β) τις αντιλήψεις που εκφράζονται μέσω της κρατικής νομοθεσίας, (γ) την κοινωνία στην οποία παρέχεται η υπηρεσία (αφού τα LLMs ρυθμίζονται ώστε να μην εκφράζονται με προσβλητικό τρόπο για κρατούντα στερεότυπα και αντιλήψεις της κοινωνίας στην οποία απευθύνονται), και (δ) τις προκαταλήψεις που περιέχει το υλικό εκπαίδευσης των LLM (π.χ. κοινωνικά στερεότυπα). Ο βαθμός στον οποίο συμβαίνει αυτό αλλάζει δυναμικά ανάλογα με τις εκάστοτε πολιτικές, αλλά συνήθως δικαιολογείται στο πλαίσιο εθνικής ασφάλειας, προστασίας των πολιτών από παραπληροφόρηση, αποφυγής παράνομων τακτικών, καταπολέμησης ψευδών ειδήσεων και ακατάλληλου περιεχομένου (από ηθικής άποψης). Καλό είναι να έχουμε υπόψη ότι μια εταιρία μπορεί να διαθέτει πολλές εκδόσεις του ίδιου LLM, κάθε μία από τις οποίες χρησιμοποιείται σε ξεχωριστές χώρες με διαφορετικά φίλτρα και ρυθμίσεις για την αξιοπιστία των πηγών. Σε κάθε περίπτωση, η επιρροή της κρατικής εξουσίας στη λειτουργία εργαλείων με ισχυρή επιρροή στην κοινή γνώμη (όπως τα LLMs και τα social media) είναι αδιαμφισβήτητη· όχι μόνο σε χώρες με αυταρχικά καθεστώτα, αλλά και στις σύγχρονες δημοκρατίες δυτικού τύπου. Αυτή η επιρροή επιτυγχάνεται είτε μέσω σχετικής νομοθεσίας, είτε με τη μετακίνηση υψηλόβαθμων κρατικών αξιωματούχων (π.χ. αξιωματούχων σε κρατικές υπηρεσίες πληροφοριών) σε καίριες θέσεις των ιδιωτικών εταιριών που αναπτύσσουν τα συστήματα αυτά.
Όλη αυτή η πραγματικότητα οδηγεί στον φόβο ότι, καθώς όλο και περισσότεροι άνθρωποι θα χρησιμοποιούν τα LLMs ως αξιόπιστη πηγή πληροφορίας, τόσο η τάση για κρατική παρέμβαση στη διαμόρφωση απόψεων μέσω των LLM θα μεγαλώνει.
Υπάρχει όμως και ένας άλλος λόγος για τον οποίο οι εταιρίες που δημιουργούν LLMs αναγκάζονται να εφαρμόσουν εκτεταμένη λογοκρισία σε αυτά. Σε αντίθεση με τα μέσα κοινωνικής δικτύωσης, που απλά φιλοξενούν περιεχόμενο το οποίο δημοσιεύεται από τους χρήστες, και άρα οι πλατφόρμες δεν μπορούν να θεωρηθούν υπεύθυνες για το περιεχόμενο αυτό, οι δημιουργοί των LLMs ισχυρίζονται ότι δεν φιλοξενούν περιεχόμενο τρίτων αλλά ότι δημιουργούν πρωτότυπο περιεχόμενο. Αυτό σημαίνει ότι ευθύνονται (σε νομικό επίπεδο) για το περιεχόμενο που παρέχει το LLM. Για να μειώσουν την έκθεση σε νομικές συνέπειες, προτιμούν να εφαρμόσουν εκτεταμένη λογοκρισία στις απαντήσεις. Κάτι παρόμοιο συμβαίνει και στις πλατφόρμες κοινωνικής δικτύωσης για πολύ συγκεκριμένες κατηγορίες περιεχομένου τις οποίες η πλατφόρμα έχει τη νομική ευθύνη να αποτρέπει (π.χ. περιεχόμενο που προστατεύεται από πνευματικά δικαιώματα, και ερωτικές υπηρεσίες).
Όταν η λογοκρισία αυτή εμφανίζεται ως «ευθυγράμμιση» με τις ανθρώπινες αξίες, τότε εγείρονται πολλά ερωτήματα σχετικά με την επικινδυνότητα αυτής της τακτικής. Το ποια θα πρέπει να είναι τα όρια των φίλτρων που εφαρμόζονται είναι ένα θέμα σίγουρα ανοιχτό προς συζήτηση· αλλά ας μην ξεχνάμε ότι εδώ δεν πρόκειται για λογοκρισία τρίτων, αλλά για αυτολογοκρισία της ίδιας της υπηρεσίας που παρέχει η εταιρία. Έχει άραγε το δικαίωμα ή όχι η εταιρία να επιλέξει πώς θα εκφραστεί μέσω των υπηρεσιών της; Ή έστω πώς θα προστατευθεί από έννομες συνέπειες και κοινωνική κριτική, έστω κι αν αυτό σημαίνει να βάλει αυστηρά όρια στις λειτουργίες των υπηρεσιών της; Όπως και να έχει, η ευθυγράμμιση της λειτουργίας των LLMs με τις κοινωνικές επιταγές δεν είναι μια εύκολη υπόθεση. Το πρόβλημα αναδύεται από το γεγονός ότι το αποτέλεσμα της αναζήτησης μιας πληροφορίας μέσω ενός LLM δεν είναι μία λίστα πηγών, όπως συμβαίνει με τις μηχανές αναζήτησης. Οι τελευταίες, μπορούν να περιέχουν μια πολυφωνία απόψεων και κάποιου είδους πιο σφαιρική πληροφόρηση, αφήνοντας στον χρήστη την τελική επιλογή των πηγών από τις οποίες θέλει να αντλήσει πληροφορία. Τώρα, το αποτέλεσμα της αναζήτησης είναι η ίδια η πηγή πληροφόρησης, και σπάνια αυτό το αποτέλεσμα περιέχει συνδέσμους προς πηγές με διαφορετική άποψη.
Ο έλεγχος της πληροφορίας είναι σημαντικό τμήμα του ανταγωνισμού που συμβαίνει αυτή τη στιγμή μεταξύ των χωρών σε θέματα τεχνητής νοημοσύνης. Γι’ αυτό μπορούμε να δούμε πολλές χώρες να εφαρμόζουν αυστηρούς κανόνες στις υπηρεσίες τεχνητής νοημοσύνης ή να αποκλείουν πλήρως υπηρεσίες τεχνητής νοημοσύνης άλλων χωρών.
4. Εκπαίδευση [63][64][65][66]
Στον τομέα της εκπαίδευσης υπάρχουν δύο κύριες ανησυχίες όσον αφορά τη χρήση συστημάτων AI:
(α) Χαμηλότερο νοητικό επίπεδο
Επισημαίνεται από αρκετούς ότι η αλόγιστη χρήση των chat bot (όπως το ChatGPT) καταστρέφει τη διαδικασία μάθησης του ανθρώπου. Η διαδικασία έρευνας, ανάλυσης, επαλήθευσης της πληροφορίας και σύνθεσης των συμπερασμάτων, παρακάμπτεται σε μεγάλο βαθμό και εφαρμόζεται μόνο ελάχιστα στο τελικό αποτέλεσμα. Στο σημείο αυτό (όταν η σύνθεση έχει ήδη γίνει), η αξιοπιστία της συγκεντρωμένης πληροφορίας δεν είναι εύκολο να επαληθευτεί. Επίσης, η τάση της ελάχιστης προσπάθειας δεν μας αφήνει να κάνουμε αλλαγές, γιατί σε πολλά σημεία το κείμενο ή η επιχειρηματολογία δεν σηκώνει διορθώσεις και θα πρέπει να φτιαχτεί από την αρχή. Επειδή αυτή η επίσπευση των εργασιών (κάθε είδους) παρακάμπτει τα στάδια που προαναφέραμε, μειώνεται και η κριτική μας ικανότητα, αφού δεν χρησιμοποιείται για το φιλτράρισμα και την επαλήθευση της πληροφορίας, αλλά και των πηγών από όπου αυτή προήλθε. Παράλληλα, η αυτόματη παραγωγή κειμένων μειώνει την εξάσκησή μας στο να συνθέτουμε προτάσεις, και άρα σκέψεις και επιχειρήματα. Κατά συνέπεια, μειώνει την ικανότητά μας να εκφραστούμε. Ανησυχίες έχουν εκφραστεί και για το γεγονός ότι πολλοί άνθρωποι δεν γράφουν ή δεν σχεδιάζουν πια με το χέρι, κάτι που μειώνει την ικανότητά μας στην ορθογραφία και το σχέδιο, και κατά συνέπεια μειώνει και την ικανότητά μας να απομνημονεύουμε και να ξεχωρίζουμε έννοιες.
(β) Αδύναμες κοινωνικές δεξιότητες και αίσθημα αλληλεγγύης
Μία από τις πιο δημοφιλείς εφαρμογές της τεχνητής νοημοσύνης στην εκπαίδευση είναι η χρήση AI εκπαιδευτών. Για παράδειγμα, οι υπηρεσίες AI εκπαιδευτών για την εκμάθηση ξένων γλωσσών που υπόσχονται επιτάχυνση της διαδικασίας και μικρότερο κόστος σε σχέση με έναν πραγματικό δάσκαλο. Το πρόβλημα είναι ότι τέτοιες προσεγγίσεις παραγνωρίζουν το γεγονός ότι η εκπαίδευση είναι μια κοινωνική δραστηριότητα. Πέρα από τις γνώσεις καθαυτές, ενσωματώνει το ενδιαφέρον για τον άλλον άνθρωπο, τη συνεργασία, την ενθάρρυνση σε περίπτωση που ο μαθητής δυσκολεύεται, την κοινωνική αλληλεπίδραση των μαθητών ή μεταξύ μαθητών και δασκάλου, τη μετάδοση αξιών και ιδανικών, τις συζητήσεις για θέματα που μας απασχολούν (εντός και εκτός του πλαισίου της ύλης), και πολλά άλλα.
Β4. Ρυθμιστικό πλαίσιο [67][68][69][70][71][72][73][74][75][76][77][61][78][79]
Το πρόβλημα της αδιαφάνειας και της αυθεντίας
Γιατί χρειαζόμαστε ένα νομοθετικό πλαίσιο το οποίο θα ρυθμίσει θέματα εφαρμογής των συστημάτων τεχνητής νοημοσύνης; Ο καλύτερος τρόπος να δώσουμε μια απάντηση είναι μέσω μερικών παραδειγμάτων.
Δεδομένου ότι τα σύγχρονα συστήματα τεχνητής νοημοσύνης (αυτά που βασίζονται στα νευρωνικά δίκτυα) αποτελούν μαύρα κουτιά, τα οποία δεν γνωρίζουμε πώς ακριβώς λειτουργούν αλλά μόνο ότι προσπαθούν να αντιγράψουν την ανθρώπινη συμπεριφορά, όπως αυτή αναγνωρίζεται μέσω κάποιων μοτίβων που εντοπίζουν στα δεδομένα εκπαίδευσης, εγείρονται κάποια ερωτήματα σχετικά με το αντίκτυπο που μπορεί να έχουν στη ζωή και τα δικαιώματα των πολιτών. Ας υποθέσουμε ότι υπάρχει ένα τέτοιο σύστημα, το οποίο αντικαθιστά τις πληροφορίες που έχει το Google Maps για τα εστιατόρια, είναι πολύ δημοφιλές, και συστήνει εστιατόρια για να δειπνήσει κάποιος ανάλογα με την περιοχή που βρίσκεται. Αν για κάποιον λόγο αποκλείσει το δικό μου εστιατόριο από τις συστάσεις, αυτό θα έχει μεγάλο αντίκτυπο στην εμπορική κίνηση του μαγαζιού μου. Μπορεί να με καταστρέψει οικονομικά. Και μάλιστα, μπορεί να έχει αποκλείσει το εστιατόριό μου για λόγους που δεν είναι καν έγκυροι ή μπορεί να μην παίζουν σημαντικό ρόλο στους περισσότερους πελάτες. Αλλά ούτε εγώ, ούτε οι υποψήφιοι πελάτες δεν γνωρίζουν τον λόγο που με έχει αποκλείσει. Απλά δεν βλέπουν την επιχείρησή μου στα αποτελέσματα. Αυτό δεν είναι το ίδιο με τις αξιολογήσεις που βλέπει κανείς στο Google Maps, όπου ναι μεν η συνολική αξιολόγηση μπορεί να φαίνεται χαμηλή, αλλά υπάρχει διαφάνεια στις κριτικές (μπορεί κάποιος να δει γιατί η αξιολόγηση είναι χαμηλή) και υπάρχουν ενδεικτικές εικόνες του μαγαζιού, των πιάτων που σερβίρονται και των τιμών. Παρόμοιες καταστάσεις μπορεί να προκύψουν για οποιοδήποτε είδος σύστασης, όπως την αγορά ενός βιβλίου πάνω σε κάποιο θέμα, την αγορά μετοχών κάποιας εταιρίας κ.ο.κ.
Ας δούμε ένα άλλο χαρακτηριστικό παράδειγμα. Στα μέσα της δεκαετίας του ‘90, όταν η πνευμονία ήταν μία από τις συχνότερες αιτίες θανάτου στις ΗΠΑ, είχε γίνει μια προσπάθεια να φτιαχτεί ένα πρόγραμμα τεχνητής νοημοσύνης το οποίο θα αναγνώριζε ποιες περιπτώσεις ασθενών με πνευμονία ανήκαν σε κατηγορία υψηλού ρίσκου και ποιες σε χαμηλού ρίσκου. Η κατηγοριοποίηση αυτή θα βοηθούσε να αποφασίσει το προσωπικό ενός νοσοκομείου το αν κάποιος ασθενής με πνευμονία θα ήταν καλύτερο να περάσει το βράδυ στο νοσοκομείο για παρακολούθηση ή αν θα μπορούσε να πάρει εξιτήριο, αφού του δοθεί η κατάλληλη αγωγή. Τα δεδομένα εκπαίδευσης που χρησιμοποιήθηκαν αφορούσαν χιλιάδες περιπτώσεις πνευμονίας, με το ιστορικό του ασθενή, και το αν ο ασθενής επέζησε από την πνευμονία. Δύο συστήματα τεχνητής νοημοσύνης εκπαιδεύτηκαν. Το πρώτο χρησιμοποιούσε τη νεότερη τεχνολογία των νευρωνικών δικτύων, και το δεύτερο πιο κλασσικούς αλγόριθμους στατιστικής ανάλυσης. Αν και το πρώτο σύστημα παρουσίαζε μεγαλύτερη ακρίβεια στις προβλέψεις του, το δεύτερο σύστημα είχε μεγαλύτερη διαφάνεια στους κανόνες που είχαν σχηματιστεί για τη λήψη αποφάσεων. Έτσι, ερευνητές που εργάζονταν στην εκπαίδευση του δεύτερου συστήματος, έτυχε να προσέξουν ότι ένας από τους κανόνες που είχε σχηματιστεί έλεγε πως «όταν ο ασθενής έχει ιστορικό άσθματος, τότε ανήκει σε κατηγορία χαμηλού ρίσκου». Από ιατρικής άποψης αυτό ήταν παράλογο. Όμως, την ίδια στιγμή, αυτό ήταν ένα μοτίβο το οποίο υπήρχε όντως στα δεδομένα και το είχαν ενσωματώσει και τα δύο συστήματα τεχνητής νοημοσύνης, λαμβάνοντας παρόμοιες αποφάσεις για τις περιπτώσεις αυτές. Αυτό που συνέβαινε ήταν ότι, στην πράξη, οι ασθενείς με πνευμονία και ιστορικό άσθματος στέλνονταν συνήθως απευθείας σε μια ΜΕΘ, ώστε να λάβουν την καλύτερη δυνατή φροντίδα. Έτσι, σπάνια κατέληγαν. Τα συστήματα AI δεν έχουν κατανόηση του πως λειτουργεί ο κόσμος· και τα δεδομένα με τα οποία εκπαιδεύονται αποτελούν σχεδόν πάντα μια μοντελοποίηση, και άρα απλοποίηση, της πραγματικότητας. Έτσι, απλά αναγνώριζαν στα δεδομένα το μοτίβο «ιστορικό άσθματος => χαμηλή θνησιμότητα». Το συμπέρασμα ήταν πως αν και το σύστημα νευρωνικών δικτύων έδινε πιο ακριβή αποτελέσματα (ως προς τα δεδομένα) σε σχέση με αυτά που έδινε το σύστημα των κλασσικών αλγορίθμων, ο τρόπος λειτουργίας (και άρα ο τρόπος που αποφασίζει τι θα δώσει στην έξοδο) του πρώτου ήταν άγνωστος ή πολύ δύσκολα ανιχνεύσιμος. Έτσι, η αξιολόγηση της σωστής λειτουργίας του ήταν πολύ πιο δύσκολη. Το σύστημα που τελικά επιλέχθηκε για χρήση ήταν το δεύτερο.
Τα παραπάνω παραδείγματα είναι χαρακτηριστικά του προβλήματος της αδιαφάνειας. Ωστόσο, υπάρχει και μια άλλη πτυχή του θέματος που αφορά το ζήτημα της αυθεντίας. Οι χρήστες συστημάτων τεχνητής νοημοσύνης διακατέχονται συχνά από έναν υπέρμετρο βαθμό εμπιστοσύνης προς τα συστήματα αυτά. Εν μέρει λόγω του θαυμασμού τους προς τις αξιοθαύμαστες ικανότητες αυτών των συστημάτων και εν μέρει λόγω της σιγουριάς και της αυτοπεποίθησης με την οποία τα συστήματα αυτά επικοινωνούν με τους χρήστες. Αυτή η αυτοπεποίθηση δημιουργεί μια ψευδαίσθηση αυθεντίας. Ο χρήστης δεν γνωρίζει ή ξεχνά ότι τα συστήματα αυτά δεν είναι αλάνθαστα, και ότι η τελική ευθύνη των ενεργειών και των αποφάσεών του ανήκει στον ίδιο. Για παράδειγμα, υπάρχουν περιπτώσεις που πολλοί οδηγοί βρέθηκαν στο αντίθετο ρεύμα όταν, ακολουθώντας τυφλά τις οδηγίες της υπηρεσίας πλοήγησης του Google Maps, θεώρησαν περιττό να κοιτάξουν τις πινακίδες. Η υπηρεσία πλοήγησης όμως εκφράζεται πάντα με σιγουριά: «στρίψτε δεξιά στα 100 μέτρα». Δεν θα πει ποτέ «σύμφωνα με τις πληροφορίες μου που ενημερώθηκαν τελευταία φορά πριν 6 μήνες, πρέπει στα 100 μέτρα να στρίψετε δεξιά» ή «αν δεν βλέπετε να γίνονται έργα, στρίψτε δεξιά στα 100 μέτρα». H πίστη ότι τα συστήματα αυτά είναι αλάνθαστα μπορεί να είναι εξαιρετικά επικίνδυνη. Και μάλιστα το ίδιο ισχύει για όλα τα πληροφοριακά συστήματα, ακόμα και αυτά που δεν χρησιμοποιούν τεχνητή νοημοσύνη. Μία άλλη χαρακτηριστική περίπτωση ήταν οι αποκλίσεις στα κατατεθειμένα ποσά που εμφάνιζε το λογιστικό σύστημα Horizon των βρετανικών ταχυδρομείων μεταξύ 1999 και 2015. Οι αποκλίσεις αυτές οδήγησαν στη δίωξη 700 υπαλλήλων για κατάχρηση. Αρκετοί από αυτούς φυλακίστηκαν, χρεωκόπησαν ή οδηγήθηκαν στην αυτοκτονία. Τελικά, αποκαλύφθηκε ότι το σύστημα Horizon είχε κάποιες κρυφές «πίσω πόρτες», οι οποίες επέτρεπαν στους προγραμματιστές να κάνουν «διορθώσεις» στις εγγραφές των ποσών που είχαν καταθέσει οι υπάλληλοι χωρίς αυτοί να το γνωρίζουν. Και μάλιστα, η εταιρία γνώριζε για τη δυνατότητα αυτή (και την πιθανή εκμετάλλευσή της από μηχανικούς) αλλά, δεδομένου ότι θα ήταν πολύ δύσκολο σε κάποιον να το αποδείξει, αρνούνταν οποιοδήποτε πρόβλημα στη λειτουργία του συστήματος για να μην αντιμετωπίσει τις εμπορικές και νομικές συνέπειες. Και φυσικά, κατά τις δίκες των ταχυδρομικών υπαλλήλων, κανένα σώμα ενόρκων δεν αμφισβήτησε την εγκυρότητα της πληροφορίας που ερχόταν από το σύστημα Horizon (τηλεοπτική σειρά «Mr Bates vs The Post Office»). Επιστρέφοντας στα συστήματα τεχνητής νοημοσύνης, ειδικότερα σε αυτά που μπορεί να έχουν σοβαρές συνέπειες στην επαγγελματική, κοινωνική ή προσωπική ζωή των πολιτών, θα πρέπει με κάποιον τρόπο να διασφαλίζεται τόσο η ασφάλεια όσο και η αξιοπρέπειά τους. Και ας μην ξεχνάμε ότι τέτοιου είδους συστήματα μπορεί να χρησιμοποιούνται σε πολλούς τομείς, όπως στον δικαστικό τομέα, στον τομέα των επενδύσεων, της εκπαίδευσης, της ιατρικής, της οδήγησης κ.α.
Αυτή η έλλειψη διαφάνειας και η απόκρυψη του βαθμού βεβαιότητας με τον οποίο λαμβάνονται οι αποφάσεις εγείρουν ερωτήματα που επεκτείνονται και σε άλλους τομείς που μπορεί να εφαρμόζονται συστήματα τεχνητής νοημοσύνης. Για παράδειγμα:
- Μπορεί η έγκριση ενός στεγαστικού δανείου να βασίζεται μόνο στην αξιολόγηση ενός συστήματος τεχνητής νοημοσύνης;
- Τι γίνεται όταν η διάγνωση ενός νοσοκομειακού ιατρού διαφωνεί με την διάγνωση του συστήματος Α.Ι που χρησιμοποιεί το νοσοκομείο;
- Μπορεί η απόφαση αποφυλάκισης ενός κρατουμένου να στηρίζεται σε ένα σύστημα τεχνητής νοημοσύνης το οποίο θα υπολογίζει πόσο πιθανή είναι η υποτροπή;
- Τι γίνεται όταν ένας έμπειρος επαγγελματίας αμφισβητεί τον τρόπο με τον οποίο το λογισμικό προσλήψεων της εταιρίας του αποφασίζει ποια βιογραφικά «αξίζουν» προσοχής;
Καλό θα ήταν λοιπόν, αν όχι αναγκαίο, να διασφαλίζονται δύο προϋποθέσεις όταν εφαρμόζουμε συστήματα Α.Ι με τέτοιο αντίκτυπο:
- διαφάνεια (αιτιολόγηση της απόφασης, βαθμός βεβαιότητας, εναλλακτικές)
- δυνατότητα αμφισβήτησης
Με άλλα λόγια, θα πρέπει τα συστήματα αυτά να μπορούν να εξηγήσουν τον τρόπο με τον οποίο αποφασίζουν γενικότερα (ποιοι παράγοντες λαμβάνονται υπόψη, ποιοι όχι, και τι βάρος έχει ο καθένας) αλλά και ειδικότερα (για ποιο λόγο μια συγκεκριμένη απόφαση φαίνεται να αποκλίνει από το σύνηθες αποτέλεσμα). Επίσης, θα πρέπει να εκφράζεται και η βεβαιότητα με την οποία λαμβάνεται μια απόφαση. Για παράδειγμα, ένα αποτέλεσμα το οποίο έχει πιθανότητα 60% να είναι σωστό είναι σίγουρα προτιμότερο από ένα άλλο το οποίο έχει πιθανότητα 45%. Αυτό όμως δεν σημαίνει ότι ο βαθμός αξιοπιστίας του πρώτου είναι μεγάλος. Οπότε, πολλές φορές θα βοηθούσε να εμφανίζονται τόσο η επιλεγμένη απόφαση με τον βαθμό βεβαιότητας που την συνοδεύει, όσο και οι υπόλοιπες εναλλακτικές (αν υπάρχουν) των οποίων ο βαθμός βεβαιότητας δεν είναι αμελητέος. Επίσης, μιλώντας για αποφάσεις οι οποίες έχουν σημαντικό αντίκτυπο στη ζωή των πολιτών θα πρέπει να παρέχεται η δυνατότητα σε κάποιον να αμφισβητήσει την απόφαση του συστήματος ΑΙ, και να ζητήσει να ελεγχθεί από άνθρωπο τόσο η εγκυρότητα των αποτελεσμάτων όσο και η αιτιολόγηση.
Αυτές τις διασφαλίσεις καλείται να παράσχει το νομοθετικό πλαίσιο. Φυσικά, η πρόοδος που υπάρχει σε κάθε χώρα στον τομέα αυτό είναι αρκετά διαφορετική και δεν στοχεύει πάντα στο ίδιο αποτέλεσμα.
Ευρώπη:
H Ευρώπη προωθεί ένα ρυθμιστικό πλαίσιο με την ονομασία Artificial Intelligence Act (AI Act), το οποίο σύμφωνα με το ίδιο έχει σκοπό να καταστήσει τα συστήματα τεχνητής νοημοσύνης ασφαλή, διάφανα (ως προς τον τρόπο λήψης των αποφάσεων), χωρίς διακρίσεις και φιλικά προς το περιβάλλον. Επίσης, για πολλά από αυτά προβλέπει την επίβλεψη από ανθρώπινο παράγοντα αντί για την πλήρη αυτοματοποίησής τους, με σκοπό να τα καταστήσει μη κοινωνικά επιβλαβή. To πλαίσιο αυτό κατατάσσει τα συστήματα τεχνητής νοημοσύνης σε τέσσερις κατηγορίες, ανάλογα με το πόσο επισφαλής μπορεί να είναι για την κοινωνία ο τρόπος χρήσης τους:
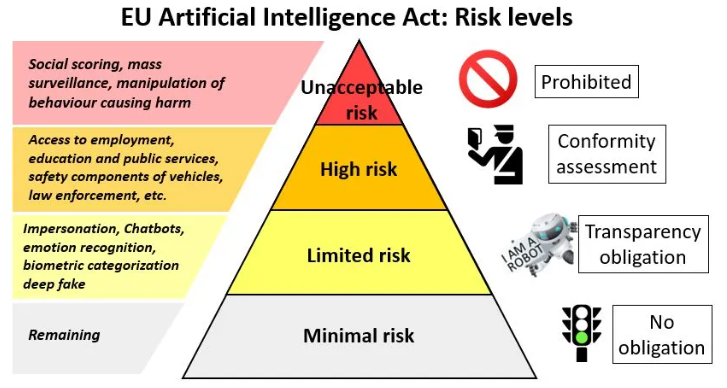
Επίπεδο 1: minimal risk (π.χ. παιχνίδια υπολογιστών ή φίλτρα ανεπιθύμητης αλληλογραφίας που ενσωματώνουν λειτουργίες AI). Καμία ρύθμιση δεν προβλέπεται για τέτοια συστήματα.
Επίπεδο 2: limited risk (π.χ. deepfakes, chatbots). Οι χρήστες θα πρέπει να ξέρουν ότι συνομιλούν/αλληλεπιδρούν με ένα σύστημα τεχνητής νοημοσύνης καθώς και ότι ένα προϊόν (ένα κείμενο, μια εικόνα, ένα ηχητικό, ένα βίντεο) είναι κατασκευασμένο από AI, εκτός κι αν είναι προφανές στον μέσο άνθρωπο (εφαρμογή από Αυγ. 2025).
Επίπεδο 3: High Risk (π.χ. συστήματα πλοήγησης, συστήματα αστυνόμευσης και συνοριακού ελέγχου, συστήματα παροχής υπηρεσιών υγείας όπως διαγνωστικά, εγχειρητικά και γενικότερα επεμβατικά στο ανθρώπινο σώμα, συστήματα αξιολόγησης μαθητών στην εκπαίδευση, συστήματα δημόσιας παρακολούθησης). Θα πρέπει να διασφαλίζεται η ασφάλεια των πολιτών, η ιδιωτικότητά τους και η αποφυγή διακρίσεων. Σε αυτά τα συστήματα απαιτείται μια διεξοδική διαδικασία εκτίμησης κινδύνων, η εκπαίδευση των συστημάτων με υψηλής ποιότητας δεδομένα, η διατήρηση αναλυτικών αρχείων καταγραφής ενεργειών (logs) και η ανθρώπινη επίβλεψη (εφαρμογή ανά κατηγορία από Αυγ. 2026 μέχρι Αυγ. 2027).
Επίπεδο 4: Unacceptable Risk (π.χ. συστήματα με άμεσο αντίκτυπο στη ζωή των πολιτών, όπως τα συστήματα κοινωνικής βαθμολόγησης σαν αυτά που εφαρμόζει η Κίνα, συστήματα κατηγοριοποίησης με βάση το φύλο ή τον σεξουαλικό προσανατολισμό, σύλληψη ή παρακολούθηση ατόμων με βάση την εκτίμηση της επικινδυνότητάς τους από συστήματα τεχνητής νοημοσύνης). Η χρήση τέτοιων συστημάτων απαγορεύεται.
Για παράδειγμα, στην Ε.Ε. η απόφαση του αν ένας άνθρωπος πρέπει να συλληφθεί γιατί εκτιμάται πως ετοιμάζεται να διαπράξει κάποιο έγκλημα δεν μπορεί να λαμβάνεται από ένα σύστημα τεχνητής νοημοσύνης. Βέβαια, η νομοθεσία προβλέπει και εξαιρέσεις (π.χ. για θέματα τρομοκρατίας), οι οποίες δεν απευθύνονται στους απλούς πολίτες αλλά σε θεσμικούς χρήστες (π.χ. μυστικές υπηρεσίες).
Σε γενικές γραμμές το πλαίσιο προσπαθεί να εξασφαλίσει ότι ένα σύστημα AI δεν θα πρέπει να παραβιάζει κάποια βασικά δικαιώματα των πολιτών όπως η αξιοπρέπεια, η ισότητα (να μην γίνονται διακρίσεις βάσει φυσικών χαρακτηριστικών), το δικαίωμα σε μια δίκαιη δίκη, το δικαίωμα της ιδιωτικότητας κ.ο.κ. Γι’ αυτό, οι παροχείς συστημάτων AI υψηλού ρίσκου θα πρέπει να παρέχουν τεχνολογική τεκμηρίωση για το πώς γίνονται κάποια πράγματα ώστε να εκτιμάται το αντίκτυπο αυτών των συστημάτων στη ζωή των ανθρώπων. Να τονίσουμε εδώ ότι το EU AI Act θα εφαρμόζεται σε κάθε υπηρεσία/προϊόν τεχνητής νοημοσύνης η οποία χρησιμοποιείται σε κράτη της Ε.Ε., ανεξαρτήτως του πού έχει αναπτυχθεί.
ΗΠΑ:
Οι ΗΠΑ κινούνται πιο αργά στον τομέα της ρύθμισης και με λιγότερες ασφαλιστικές δικλείδες, κυρίως για λόγους ανταγωνιστικότητας (ιδιαίτερα απέναντι στην Κίνα). Τον Ιανουάριο του 2025 ο Τραμπ εξέδωσε ένα προεδρικό διάταγμα με το οποίο ανακαλούσε κάποιες ρυθμίσεις που είχε εφαρμόσει ο Μπάιντεν πάνω στην ανάπτυξη συστημάτων ΑΙ. Στην ουσία αφαίρεσε διάφορα εμπόδια στην ταχεία ανάπτυξη συστημάτων ΑΙ, όπως κάποιες προβλέψεις για κυβερνητική επίβλεψη της πληροφορίας που παρείχαν αυτά τα συστήματα σε επίπεδο ορθότητας και ηθικής. Μια κίνηση προς την επιτάχυνση της δημιουργίας ενός ρυθμιστικού πλαισίου έγινε τον Σεπτέμβριο του 2025 σε πολιτειακό επίπεδο από την Καλιφόρνια με το "Frontier AI Bill", γνωστό και ως Senate Bill 53 (SB 53), το οποίο είχε ως σκοπό να ρυθμίσει τους μεγάλους παίχτες της αγοράς AI, απαιτώντας να αποκαλύπτουν σημαντικά περιστατικά ασφάλειας ή δυσλειτουργίας που συμβαίνουν σε τέτοια συστήματα, να λαμβάνουν μέτρα για αποζημιώσεις δυσλειτουργίας, να δημοσιεύουν τις προδιαγραφές ασφάλειας που χρησιμοποιούν και να προστατεύουν τους πληροφοριοδότες για τέτοια θέματα. Η «απάντηση» της ομοσπονδιακής κυβέρνησης ήρθε μόλις τρεις μήνες μετά, τον Δεκέμβριο, όταν ο Τραμπ εξέδωσε ένα προεδρικό διάταγμα το οποίο εμποδίζει κάθε πολιτεία να ψηφίζει τους δικούς της ρυθμιστικούς νόμους για την εφαρμογή συστημάτων τεχνητής νοημοσύνης. Το σκεπτικό ήταν ότι θα έπρεπε να δημιουργηθεί ένα ρυθμιστικό πλαίσιο σε ομοσπονδιακό επίπεδο το οποίο θα επιτρέψει την απρόσκοπτη καινοτομία στον τομέα αυτό.
Κίνα:
Φαίνεται πως η Κίνα έχει ήδη κάνει αρκετά βήματα στη ρύθμιση αρκετών τομέων χρήσης της τεχνητής νοημοσύνης, όπως τα recommendation systems (2021), τη δημιουργία deepfakes (2022) και τα LLMs (2023) για τα οποία απαιτείται ειδική αδειοδότηση. Η ταχύτητα με την οποία προχωρά η ρύθμιση στην Κίνα οφείλεται στο γεγονός ότι οι εταιρίες έχουν πολύ μικρή διαπραγματευτική ισχύ απέναντι στην κυβέρνηση, μιας και οι εμπλεκόμενοι στη διαδικασία βρίσκονται σε μια ιεραρχική σχέση· με την κυβέρνηση στην κορυφή, τις ρυθμιστικές αρχές ακριβώς από κάτω, και τις εταιρίες τεχνολογίας ακόμα πιο κάτω. Από την άλλη όμως, τα προβλήματα που δημιουργεί το ρυθμιστικό πλαίσιο στην τεχνολογική ανάπτυξη δεν επικοινωνούνται έγκαιρα προς την κορυφή της ιεραρχίας, και έτσι η αντιμετώπιση των προβλημάτων είναι αργή. Αλλαγές στο ρυθμιστικό πλαίσιο γίνονται μόνο όταν ένα πρόβλημα έχει αποκτήσει μεγάλες διαστάσεις. Από την άλλη, το ρυθμιστικό πλαίσιο ασχολείται κυρίως με τον έλεγχο του περιεχομένου στο διαδίκτυο. Δηλαδή, τον έλεγχο της διάδοσης απόψεων μέσω των νέων συστημάτων AI στα οποία η έξοδος δεν είναι ντετερμινιστική. Μία από τις δυσκολίες που αντιμετωπίζει η Κίνα αφορά τις πηγές δεδομένων που θα χρησιμοποιηθούν για την εκπαίδευση αυτών των συστημάτων AI, γιατί η πληροφορία (σε διαδίκτυο, βιβλία κ.λπ.) που είναι βασισμένη σε άλλες γλώσσες (και ιδιαίτερα στην αγγλική) πρέπει να «φιλτραριστεί» ώστε να ευθυγραμμιστεί με τις πολιτικές της κινεζικής κυβέρνησης πριν χρησιμοποιηθεί. Πάνω σε αυτό υπάρχει μια συντονισμένη προσπάθεια ανάμεσα σε εταιρίες του ιδιωτικού και του δημοσίου τομέα. Επίσης, το πλαίσιο ενδιαφέρεται βασικά για συστήματα AI που χρησιμοποιούνται σε υπηρεσίες και προϊόντα τα οποία απευθύνονται στο ευρύ κοινό, και όχι αυτά που είναι για στοχευμένη χρήση από ιδιωτικές εταιρίες. Για παράδειγμα, το Copilot της Microsoft δεν χρειάζεται να λάβει κάποια αδειοδότηση για να χρησιμοποιηθεί από τις κινέζικες εταιρίες.
Υπόλοιπος κόσμος:
Η Ινδία δεν έχει κανένα περιορισμό, αλλά αντίθετα επικεντρώνεται στην προσέλκυση επενδύσεων πάνω στην τεχνητή νοημοσύνη. Στη Βραζιλία έχει περάσει ένα νομοσχέδιο το οποίο προβλέπει αποζημίωση σε καλλιτέχνες των οποίων οι δημιουργίες έχουν χρησιμοποιηθεί για την εκπαίδευση συστημάτων AI και έχουν απαγορευτεί τα αυτόνομα οπλικά συστήματα. Είναι ενδιαφέρον πως η Γαλλία έχει ένα δόγμα βάσει του οποίου συστήματα μάχης τα οποία είναι αυτοματοποιημένα δεν επιτρέπεται να αποφασίζουν από μόνα τους αν θα σκοτώσουν ή όχι. Για την ώρα, η χρήση της τεχνητής νοημοσύνης στη Γαλλία περιορίζεται στην επιτάχυνση των αποφάσεων και την καλύτερη εκτίμηση της κατάστασης στο πεδίο της μάχης.
Δείτε επίσης: Τεχνητή Νοημοσύνη - Μέρος Α: Πως λειτουργούν τα συστήματα Α.Ι και μέχρι που μπορούν να φτάσουν
Αναφορές:
[1]. «Andrej Karpathy: Software Is Changing (Again)», Y Combnator, 2025
[2]. «How AI will change software engineering – with Martin Fowler», The Pragmatic Engineer, 2025
[3]. «Why replacing developers with A.I is going horribly wrong», Mackard, 2026
[4]. «The road toward more driverless cars», CBS Sunday Morning, 2025
[5]. «Self-Driving Car? Does it Work?!», The 8-bit Guy, 2025
[6]. «Tesla Full Self Driving explained by Andrej Karpathy», Tesla Owners Online, 2024
[7]. «How Aurora Got Self-Driving Trucks On The Road», CNBC, 2023
[8]. «The Quiet Race to Build Self-Driving Trucks in the US and Europe», Bloomberg Television, 2025
[9]. «How AI is Revolutionizing Medicine», Bloomberg Originals, 2025
[10]. «Why Doctors Say OpenEvidence Is A ‘Game Changer’», Bloomberg Television, 2025
[12]. «Novartis CEO discusses how AI will impact drug development», Yahoo Finance, 2024
[14]. «A quest for a cure: AI drug design | Isomorphic Labs», Google DeepMind, 2025
[16]. «How artificial intelligence is transforming the defence industry», FRANCE 24 English, 2025
[17]. «This Is How AI Is Rewriting the Rules of War», Johnny Harris, 2025
[18]. «The AI Arsenal That Could Stop World War III», Palmer Luckey | TED, 2025
[19]. «We Saw A New AI-Piloted Fighter Drone About To Transform Warfare», CNBC, 2025
[20]. «These Palantir AI Military Products Are Actually Scary», Silicon Money, 2025
[24]. «Industrial robots are (nearly) perfect», Atomic Frontier, 2025
[25]. «World’s most advanced robotic warehouse (AI automation)», Brightpick, 2024
[27]. «I Tried the First Humanoid Home Robot. It Got Weird. | WSJ», The Wall Street Journal, 2025
[28]. «Pick, Carry, Place, Repeat | Inside the Lab with Atlas», Boston Dynamics, 2025
[30]. «Google DeepMind robotics lab tour with Hannah Fry», Google DeepMind, 2025
[32]. «Optimus Builds Optimus 3 - Inside The First Optimus Factory», Pro Robots, 2025
[33]. «China’s Robots Are Crazier Than You Think», The Invisible Game, 2025
[34]. «Future of Work 2026: The Only Jobs That Will Survive the AI Era», Silicon Valley Girl, 2026
[35]. «AI Can Only Do 5% of Jobs: MIT Economist Fears Crash», Bloomberg Technology, 2024
[38]. «How Amazon replaced an entire workforce with robots», Compaxis, Nov. 2025
[39]. «The truth about A.I and the mass layoffs», CNBC, Nov. 2025
[40]. «What everyone is getting wrong about A.I and jobs», Y Combinator, Oct. 2025
[41]. «The A.I rollout is here - and it's messy», Financial Times, Oct. 2025
[42]. «Why companies are lying about mass layoffs», Damon Cassidy, Oct. 2025
[43]. «Why has the COVID-19 pandemic increased support for Universal Basic Income?», 2021
[44]. «Andrew Yang Makes the Case for Universal Basic Income», Ben Shapiro, 2021
[45]. «A Basic Income for All: Dream or Delusion?», World Economic forum, 2017
[46]. «How South Korea Experiments With Universal Basic Income | WSJ», The Wall Street Journal, 2020
[48]. «Basic Income: The Free Money Experiments | Moving Upstream», The Wall Street Journal, 2017
[50]. «A Universal Basic Income is bad for social justice», Transforming Society, 2023
[51]. «Why a universal basic income is a poor substitute for a guaranteed job», ABC, 2017
[52]. «Why AI Has a Plagiarism Problem», PlagiarismToday, 2024
[54]. «AI deepfakes are costing billions in fraud. Can you detect one?», NBC Bay Area, 2025
[55]. «Voice fraud scams company out of $243,000», Avast Blog, 2019
[57]. «AI Alignment Is Censorship», Reboot, 2025
[58]. «Large Language Models will be Great for Censorship», LessWrong, 2023
[60]. «Censorship Techniques in LLMs: Pros, Cons, and Global Regulations», 2025
[61]. «The Alignment Problem: Machine Learning And Human Values», Brian Christian, Ww Norton & Co, 2021
[62]. «Προπαγάνδα και παραπληροροφόρηση στο ίντερνετ», Άρης Χατζηστεφάνου, Εκδόσεις Τόπος, 2025
[64]. «How ChatGPT Slowly Destroys Your Brain», Justin Sung, 2025
[65]. «ChatGPT May Be Eroding Critical Thinking Skills, According to a New MIT Study», TIME, 2025
[67]. «Will AI Laws Protect Us? EU AI Act Explained », DW Shift, 2025
[68]. «The EU's AI Act Explained», EU Made Simple, 2024
[69]. «EU AI Act Explained: Everything You Must Know», Deloitte Nederland, 2024
[70]. «The Data Chronicles: The EU AI Act | What you need to know», Hogan Lovells, 2024
[73]. «Will AI Laws Protect Us? EU AI Act Explained », DW Shift, 2025
[74]. «The EU's AI Act Explained», EU Made Simple, 2024
[75]. «EU AI Act Explained: Everything You Must Know», Deloitte Nederland, 2024
[76]. «Weapons of Math Destruction | Cathy O'Neil», Talks at Google, 2016
[77]. «The Potential Pitfalls of Machine Learning Algorithms in Medicine», Pulmonology Advisor, 2017
[78]. «The human interface: When machines become more human than humans», Gari Johnson, Gari Johnson Books, 2025
[79]. «Weapons of Math Destruction», Cathy O’Neil, Penguin Books, 2016











