

Τεχνητή Νοημοσύνη - Μέρος Α
Α1. Τι είναι η τεχνητή νοημοσύνη;
Η ιδέα της Τεχνητής Νοημοσύνης (Artificial Intelligence ή A.I) ξεκινά στα μέσα του 20ού αιώνα, κυρίως ως αποτέλεσμα επιστημονικής φαντασίας. Tο 1950 ο μαθηματικός Άλαν Τιούρινκ, πατέρας της «επιστήμης των υπολογιστών», θα θέσει το ερώτημα αν οι μηχανές μπορούν να σκεφτούν. H αρχική ενασχόληση με το αντικείμενο ήταν κυρίως θεωρητική, χωρίς πρακτικές εφαρμογές. Αν και οι βάσεις των τεχνολογιών που χρησιμοποιούνται σήμερα σε εφαρμογές τεχνητής νοημοσύνης τέθηκαν την περίοδο μεταξύ του Β’ Παγκοσμίου Πολέμου και του 1970, οι περιορισμοί στην υπολογιστική ισχύ και στα διαθέσιμα δεδομένα κράτησαν τις προσδοκίες χαμηλά, μέχρι τη δεκαετία του 1980. Η ταχεία εξέλιξη των υπολογιστών και της επιστήμης των μικροεπεξεργαστών τη δεκαετία του ‘70 και του ‘80 έδωσε νέα ώθηση στον τομέα της τεχνητής νοημοσύνης. Οι πραγματικές όμως δυνατότητες ανάπτυξης εμπορικών εφαρμογών ήρθαν με την ανάπτυξη του διαδικτύου και της ψηφιοποίησης βιβλίων και περιοδικών, που έκανε τεράστιο όγκο δεδομένων διαθέσιμο για την εκπαίδευση και την αξιολόγηση συστημάτων τεχνητής νοημοσύνης.
Για την πλειοψηφία του κόσμου, η έννοια της τεχνητής νοημοσύνης ήταν γνωστή μόνο μέσω κινηματογραφικών παραγωγών, όπως το «A Space Odyssey» (1968), το «Blade Runner» (1982), το «Terminator» (1984), ή το «I, Robot» (2004), και ήταν συνδεδεμένη με μηχανές που είχαν νοημοσύνη εφάμιλλη, αν όχι ανώτερη, του ανθρώπου· και οι οποίες ανέπτυσσαν κάποιου είδους αυτοσυνειδησία και, ως εκ τούτου, ανεξαρτησία στις ενέργειές τους και τη λήψη αποφάσεων (κάτι που, στις ταινίες, συχνά οδηγούσε σε επανάσταση των μηχανών ενάντια στον άνθρωπο). Γι’ αυτό, τις τελευταίες δεκαετίες, η έρευνα πάνω σε τέτοιες τεχνικές και τεχνολογίες χρησιμοποιούσε ορολογία που συνδέονταν με πιο ρεαλιστικές προσδοκίες, όπως «αναγνώριση προτύπων», «μηχανική μάθηση» κ.ά. Τα τελευταία χρόνια, με την εξάπλωση της χρήσης τέτοιων τεχνικών σε εμπορικές αλλά και στρατιωτικές εφαρμογές, ο όρος «τεχνητή νοημοσύνη» έχει επιστρέψει, κυρίως για λόγους εμπορικής προώθησης.
Κάπου εδώ είναι καλό να δώσουμε έναν πρώτο, απλό και περιγραφικό ορισμό για τον όρο «τεχνητή νοημοσύνη», ώστε να αποφύγουμε παρεξηγήσεις. Με τον όρο «τεχνητή νοημοσύνη» αναφερόμαστε στην ικανότητα μιας μηχανής-υπολογιστή να προσομοιώνει την ανθρώπινη νοημοσύνη. Όπως θα δούμε και παρακάτω, αυτό δεν σημαίνει ότι ο υπολογιστής λειτουργεί με τον ίδιο τρόπο που λειτουργεί η ανθρώπινη νοημοσύνη, αλλά απλώς ότι παράγει αποτελέσματα παρόμοια με αυτά που θα παρήγαγε και ένας άνθρωπος (ίσως, βέβαια, λειτουργεί σαν την ανθρώπινη σε μια υπεραπλουστευμένη μορφή— ή ίσως, και αυτό είναι το πιθανότερο, εμείς νομίζουμε ότι το κάνει επειδή δεν ξέρουμε πως πραγματικά λειτουργεί η ανθρώπινη νοημοσύνη). Κάποιες περιπτώσεις που δείχνουν ότι η τεχνητή νοημοσύνη δίνει απαντήσεις που προσομοιάζουν με τις αντίστοιχες ανθρώπινες, είναι, για παράδειγμα, το να της κάνεις μια ερώτηση και να σου δώσει μια απάντηση με τρόπο παρόμοιο με αυτόν που θα περίμενες από έναν άνθρωπο. Ή, να της δώσεις μια εικόνα και να δώσει μια περιγραφή του τι δείχνει η εικόνα αυτή. Ακόμα, να της δώσεις ένα κείμενο, και να σου παραγάγει ένα ηχητικό το οποίο να αποτελεί την ανάγνωση του κειμένου, ή και να της δώσεις ένα ηχητικό και να σου πει αν περιέχει μια ανθρώπινη ομιλία, ένα τραγούδι ή κάτι άλλο (π.χ. τον ήχο απογείωσης ενός αεροπλάνου). Όπως καταλαβαίνετε, σε κάθε περίπτωση, το υπολογιστικό μας σύστημα, δέχεται μια είσοδο και επιστρέφει μια έξοδο. Στην περίπτωση της ερώτησης και απάντησης, η είσοδος είναι κείμενο (ερώτηση) και η έξοδος πάλι κείμενο (απάντηση). Στην περίπτωση της περιγραφής μιας εικόνας, η είσοδος είναι εικόνα και η έξοδος κείμενο. Στην περίπτωση της ανάγνωσης του κειμένου, η είσοδος είναι κείμενο και η έξοδος ήχος.
Η είσοδος και η έξοδος μπορούν να είναι οποιασδήποτε μορφής (κείμενο, εικόνα, ήχος, βίντεο κ.ο.κ.) αρκεί η μορφή αυτή να μπορεί να ψηφιοποιηθεί. Δηλαδή, να αναπαρασταθεί με μαθηματική μορφή. Για παράδειγμα, ένα κείμενο μπορεί να αναπαρασταθεί μαθηματικά αν αντιστοιχίσουμε κάθε χαρακτήρα του κειμένου (γράμματα, σημεία στίξης, κενά, παράγραφοι κ.λπ.) με έναν αριθμό. Αντίστοιχα, μια εικόνα χωρίζεται σε πολύ μικρά τμήματα (στο μέγεθος μιας κουκίδας), τα οποία ονομάζονται pixels, καθένα από τα οποία έχει ένα συγκεκριμένο χρώμα και μπορεί να εκφραστεί με μια τριάδα αριθμών. Άρα, πρώτο και πολύ βασικό συμπέρασμα για τον τρόπο που λειτουργούν τα υπολογιστικά συστήματα, είναι ότι δεν αντιλαμβάνονται τα φυσικά μεγέθη ή χαρακτηριστικά όπως τα αντιλαμβάνεται ο άνθρωπος (χρώματα, σχήματα κ.λπ.), αλλά αντιλαμβάνονται μόνο την μαθηματική τους «μετάφραση» (την αριθμητική αναπαράσταση στην οποία έχει μετατραπεί η κάθε πληροφορία).
Α2. Βασικές αρχές λειτουργίας
Ας δούμε τώρα ένα πολύ απλό παράδειγμα τρόπου λειτουργίας της τεχνητής νοημοσύνης. Έστω ότι έχουμε ένα πρόγραμμα υπολογιστή (λογισμικό) το οποίο μπορεί, μέσω μαθηματικών πράξεων, να υπολογίσει 2 συγκεκριμένα χαρακτηριστικά για μια εικόνα. Τα χαρακτηριστικά που υπολογίζει είναι: (α) πόσο έντονα είναι τα χρώματα της εικόνας, και (β) πόσο λεία είναι η υφή αυτού που απεικονίζεται (δηλαδή κατά πόσο υπάρχουν απότομες εναλλαγές στα χρώματα). Το κάθε χαρακτηριστικό εκφράζεται με μια τιμή από 0 έως 1 (π.χ. 0 για καθόλου έντονα χρώματα, όπως μια εντελώς μαύρη ή εντελώς άσπρη εικόνα, και 1 για πολύ έντονα, όπως μια εικόνα με έντονο κόκκινο ή έντονο πράσινο κ.λπ.).
Το πρόγραμμα αυτό έχει δύο καταστάσεις λειτουργίας. Στην πρώτη, τη λειτουργία εκπαίδευσης, του δίνουμε εικόνες οι οποίες συνοδεύονται από μια «ετικέτα» (μια περιγραφή του τι δείχνει η εικόνα). Το πρόγραμμα υπολογίζει τα παραπάνω 2 χαρακτηριστικά για κάθε εικόνα, και αποθηκεύει τα χαρακτηριστικά μαζί με την ετικέτα. Άρα, σε αυτό το στάδιο, ξεκινάμε να του δίνουμε εικόνες από κόκκινα μήλα και από πορτοκάλια μαζί με μια ετικέτα που λέει "μήλα" ή "πορτοκάλια". Για κάθε εικόνα, το πρόγραμμα αποθηκεύει προσωρινά την εξής πληροφορία: [ετικέτα, ένταση χρωμάτων, λεία υφή], π.χ.:
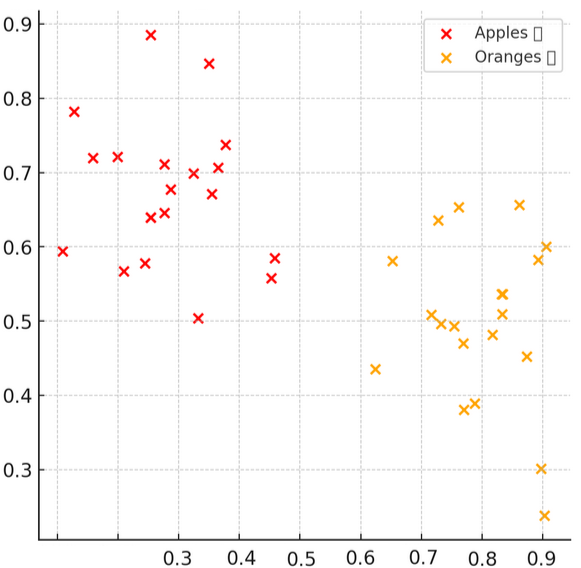
[πορτοκάλια, 0.8, 0.5], [μήλα, 0.5, 0.83], [μήλα, 0.45, 0.75], [πορτοκάλια, 0.78, 0.44]
Στο παρακάτω διάγραμμα απεικονίζουμε τις αποθηκευμένες τιμές από τα δείγματα των εικόνων που χρησιμοποιούμε για την εκπαίδευση του προγράμματος, όπου ο οριζόντιος άξονας είναι η ένταση των χρωμάτων, και ο κάθετος η υφή. Κάθε «x» αντιπροσωπεύει και μια εικόνα.
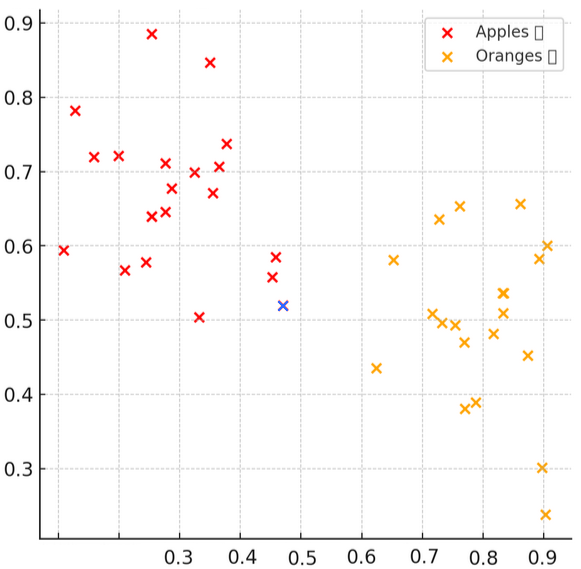
Η δεύτερη κατάσταση λειτουργίας είναι η κανονική λειτουργία, όπου του δίνουμε μια εικόνα χωρίς ετικέτα (δηλαδή, δεν του λέμε αν η εικόνα δείχνει κόκκινα μήλα ή πορτοκάλια). Αντίθετα, του ζητάμε να προσθέσει εκείνο την ετικέτα. To πρόγραμμα υπολογίζει τα χαρακτηριστικά της νέας εικόνας, η οποία φαίνεται με μπλε στο επόμενο διάγραμμα, και στη συνέχεια εκτιμά ότι τα χαρακτηριστικά της νέας εικόνας είναι πιο κοντά σε αυτά των εικόνων που είχαν ετικέτα «μήλα». Οπότε αποφασίζει να δώσει την ετικέτα «μήλα» στην νέα εικόνα (η ετικέτα είναι και η έξοδος του συστήματος).
Για τη λήψη αυτής της απόφασης χρησιμοποιείται ένας αλγόριθμος, τον οποίο έχουμε ορίσει εμείς μέσα στο πρόγραμμα. Υπάρχουν πολλοί αλγόριθμοι που μπορεί να χρησιμοποιηθούν. Για παράδειγμα, με βάση τις εικόνες που έχει εκπαιδευτεί, μπορεί να ορίσει ένα όριο (με τη μορφή μιας γραμμής), όπως φαίνεται στο επόμενο διάγραμμα. Κάθε νέα εικόνα με χαρακτηριστικά που βρίσκονται δεξιά αυτού του ορίου θεωρείται ότι απεικονίζει πορτοκάλια, και κάθε εικόνα με χαρακτηριστικά αριστερά αυτού του ορίου ότι απεικονίζει μήλα. Η θέση του ορίου αποφασίζεται κατά τη διάρκεια της εκπαίδευσης με βάση τα δείγματα που χρησιμοποιούνται.
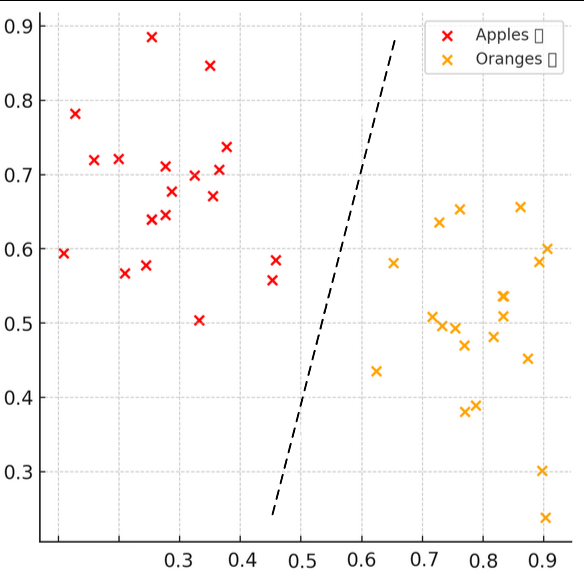
Εναλλακτικά, θα μπορούσαμε να υπολογίσουμε το «κέντρο βάρους» των χαρακτηριστικών για εικόνες με μήλα (δηλαδή, τη μέση τιμή των χαρακτηριστικών τους βάσει της θέσης τους στο διάγραμμα), και το αντίστοιχο κέντρο βάρους για τις εικόνες με πορτοκάλια, και να πάρουμε την απόφαση (να κάνουμε δηλαδή την κατάταξη), κοιτώντας σε ποιο από τα δύο κέντρα βάρους βρίσκεται πιο κοντά η νέα εικόνα. Σε κάθε περίπτωση, θα πρέπει να γνωρίζουμε ότι τα δείγματα εκπαίδευσης δεν αποθηκεύονται από το σύστημά μας. Αυτό που αποθηκεύεται κατά την εκπαίδευση είναι οι πιθανοί έξοδοι («μήλα» , «πορτοκάλια») και κάποιες παράμετροι οι οποίες θα χρειαστούν για να αποφασίζεται η έξοδος κατά την κανονική λειτουργία. Στη μία περίπτωση οι παράμετροι ορίζουν τη θέση του ορίου (ευθείας γραμμής), και στην άλλη ορίζουν το κέντρο βάρους κάθε ομάδας δειγμάτων.
Αυτή η διαδικασία εκπαίδευσης που περιγράψαμε πιο πάνω είναι ένα παράδειγμα μηχανικής μάθησης· και η εργασία την οποία «μαθαίνει» το πρόγραμμα λέγεται «κατάταξη». Η διαδικασία της κατάταξης που το πρόγραμμά μας είναι ικανό να κάνει μετά την εκμάθηση, είναι στην ουσία μια μορφή τεχνητής νοημοσύνης. Δίνουμε ως είσοδο μια εικόνα και παίρνουμε ως έξοδο κείμενο (μια ετικέτα). Το πρόγραμμα λειτουργεί αναγνωρίζοντας μοτίβα στις εισόδους που του παρέχουμε. Δηλαδή, αναγνωρίζει ότι στις εικόνες που δείχνουν κόκκινα μήλα οι τιμές κάποιων υπολογιζόμενων χαρακτηριστικών (όχι απαραίτητα όλων) βρίσκονται σε μια συγκεκριμένη περιοχή, ενώ οι τιμές των εικόνων που δείχνουν πορτοκάλια βρίσκονται σε μια άλλη. Και αυτό συμβαίνει πάντα, ή σχεδόν πάντα. Δηλαδή, είναι ένα μοτίβο. Τα μοτίβα αυτά αποτυπώνονται στις υπολογιζόμενες παραμέτρους.
Όπως ίσως να υποψιάζεστε, κάθε φορά που το πρόγραμμα δίνει μια έξοδο το κάνει με έναν βαθμό βεβαιότητας που δεν είναι πάντα ο ίδιος. Στο παράδειγμά μας, αν μια εικόνα είχε τιμές κοντά στη διαχωριστική γραμμή, τότε το πρόγραμμα επιλέγει την ετικέτα (έξοδο) με μικρό βαθμό βεβαιότητας. Αντίθετα, αν οι τιμές βρίσκονται μακριά από τη διαχωριστική γραμμή, το πρόγραμμα επιλέγει την έξοδο με μεγάλο βαθμό βεβαιότητας. Πως το κάνει όμως αυτό; Για κάθε δυνατή έξοδο (από αυτές που έχει συναντήσει κατά την εκπαίδευσή του) υπολογίζει την πιθανότητα αυτή να είναι και η σωστή (η πιο κατάλληλη). Στην συνέχεια, επιλέγει αυτή με την μεγαλύτερη πιθανότητα. Ο βαθμός βεβαιότητας που αντιστοιχεί στην έξοδο που λαμβάνουμε δεν είναι γνωστός σε εμάς. Μπορεί η έξοδος που επιλέχθηκε να είχε πιθανότητα 98% ή μπορεί και να είχε πιθανότητα 22%. Προφανώς, όλες οι άλλες είχαν μικρότερη πιθανότητα, γι αυτό και επιλέχθηκε αυτή. Όταν λοιπόν ο βαθμός βεβαιότητας είναι μικρός, τότε ανάλογα με το πως το πρόγραμμα είναι ρυθμισμένο, μπορεί (α) να αρνηθεί να μας δώσει κάποια έξοδο (να δώσει μια ετικέτα στην εικόνα), (β) να δώσει μια ετικέτα αλλά παράλληλα να μας προειδοποιήσει ότι δεν είναι και πολύ σίγουρο για την ορθότητά της, ή (γ) να μας δώσει μια ετικέτα χωρίς να μας προειδοποιήσει για την πιθανότητα λάθους, για να μην υποσκάψει την αξιοπιστία του.
Α3. Τρόποι εκπαίδευσης ενός συστήματος A.I [1]
Υπάρχουν δύο βασικές μέθοδοι με τις οποίες ένα σύστημα τεχνητής νοημοσύνης μπορεί να «μάθει» πως να δίνει καλύτερες εξόδους. Η πρώτη είναι αυτή που περιγράψαμε στο προηγούμενο παράδειγμα και είναι, στην ουσία, η μίμηση. Δίνουμε στο σύστημα έναν αριθμό από δείγματα εισόδου-εξόδου, και αυτό προσπαθεί να «καταλάβει» τη λογική με την οποία εμείς αντιστοιχίζουμε κάθε είσοδο με μια συγκεκριμένη έξοδο (με άλλα λόγια, προσπαθεί να εντοπίσει το μοτίβο που συνδέει την είσοδο με την επιθυμητή έξοδο). Αυτό το κάνει μέσω μιας στατιστικής ανάλυσης, η οποία ανιχνεύει σχέσεις μεταξύ της εισόδου (των τιμών που παίρνουν τα χαρακτηριστικά της εισόδου) και της εξόδου.
Η δεύτερη μέθοδος είναι αυτή που αποκαλούμε «ενισχυτική μάθηση» (Reinforcement Learning ή RL) και λειτουργεί δίνοντας στο σύστημα μια εργασία/στόχο που πρέπει να πετύχει, καθώς και έναν τρόπο (μια συνάρτηση) να αντιληφθεί αν πλησιάζει ή απομακρύνεται από αυτόν το στόχο. Για να εφαρμοστεί αυτή η μέθοδος πρέπει το σύστημα να έχει ένα «μοντέλο του κόσμου» στο οποίο η μέθοδος μπορεί να λειτουργεί: αυτό ονομάζεται “world model”, και αφορά το πώς ορίζεται η κατάσταση του κόσμου, όπως τον αντιλαμβάνεται το σύστημα ΑΙ. Για παράδειγμα, το μοντέλο του κόσμου για ένα πρόγραμμα που παίζει σκάκι είναι η σκακιέρα, με τις θέσεις των κομματιών πάνω σε αυτή. Η είσοδος εδώ ορίζεται από το τι κομμάτι περιέχει καθένα από τα 64 τετράγωνα της σκακιέρας, και η κάθε έξοδος αφορά καθεμία από τις δυνατές κινήσεις κομματιών που μπορεί να κάνει ο παίκτης μας σε μια συγκεκριμένη κατάσταση. Αν στο πρόγραμμα που παίζει σκάκι εφαρμόσουμε ενισχυτική μάθηση, τότε αυτό θα αρχίσει να κάνει τυχαίες κινήσεις· και μετά από κάθε κίνηση (αφού έχει παίξει και ο αντίπαλος) θα αξιολογεί αν η κατάσταση στη σκακιέρα είναι καλύτερη από πριν (αν το έχει φέρει πιο κοντά στη νίκη) ή όχι. Αν ναι, τότε η κίνηση που έκανε είναι πιο πιθανό να επαναληφθεί στο μέλλον, αν βρεθεί στην ίδια ή σε παρόμοια κατάσταση. Με άλλα λόγια, δεν χρειάζεται να του δώσουμε δείγματα από παρτίδες άλλων παιχτών για να τα χρησιμοποιήσει ώστε να μιμηθεί τον τρόπο παιξίματος αυτών που κέρδιζαν. Μπορεί να φτιάξει μόνο του δείγματα από παρτίδες, επιλέγοντας τυχαίες κινήσεις μέχρι να μάθει (από τις επιτυχίες του και τα λάθη του) να κάνει κινήσεις που είναι λιγότερο τυχαίες, και οδηγούν στην επιτυχία με μεγαλύτερη πιθανότητα.
Επομένως, στη διαδικασία της μίμησης λέμε στη μηχανή «κάνε ό,τι κάνω με τη μεγαλύτερη δυνατή ακρίβεια» (διδάσκουμε εμείς τη μηχανή τόσο ως προς τα δεδομένα, όσο και ως προς τον τρόπο με τον οποίο μπορεί να κάνει την κατάταξη με ακρίβεια), ενώ στη διαδικασία της ενισχυτικής μάθησης της λέμε «εξερεύνησε τυχαία κάθε επιλογή, εστίασε στις επιλογές που σε φέρνουν πιο κοντά στο επιθυμητό αποτέλεσμα, και επανάλαβέ τες μέχρι να μάθεις να φτάνεις στο επιθυμητό αποτέλεσμα με τον πιο αποτελεσματικό τρόπο».
Σχεδόν όλα τα σύγχρονα εμπορικά εργαλεία τεχνητής νοημοσύνης εκπαιδεύονται μέσω μίμησης. Η ενισχυτική μάθηση χρησιμοποιείται σπάνια, ιδιαίτερα σε εμπορικές εφαρμογές. Αυτό συμβαίνει γιατί, στις περισσότερες περιπτώσεις, είναι πολύ δύσκολο να μοντελοποιήσουμε μαθηματικά το περιβάλλον λειτουργίας (world model), τον στόχο (την εργασία που πρέπει να εκτελεστεί) ή τον τρόπο με τον οποίο υπολογίζεται αν μια έξοδος μας έφερε πιο κοντά στον στόχο (ή και τα δύο). Ακόμα και αν ο στόχος είναι κάτι που εμείς θεωρούμε απλό, όπως το να κερδίσουμε μια παρτίδα σκάκι. Επίσης, η εκπαίδευση στο RL απαιτεί να μην υπάρχει σημαντικό κόστος από τα λάθη που θα κάνει το σύστημά μας από τυχαίες εξόδους καθώς μαθαίνει. Για τον λόγο αυτό, στη συνέχεια επικεντρωνόμαστε κυρίως στα συστήματα τεχνητής νοημοσύνης που βασίζονται στη μίμηση.
Α4. Αυξάνοντας την πολυπλοκότητα και τις δυνατότητες
Το παραπάνω παράδειγμα (μήλα-πορτοκάλια) ήταν απλό, αλλά δίνει τα βασικά στοιχεία λειτουργίας και των πιο σύνθετων συστημάτων. Αν θέλουμε το σύστημά μας να μπορεί να αναγνωρίσει περισσότερες εικόνες (όπως αντικείμενα, ανθρώπους, κτίρια κ.λπ.), αλλά και να μπορεί να αναγνωρίσει περισσότερη πληροφορία για το καθένα (π.χ. δεν είναι απλά άνθρωπος αλλά είναι νεαρός άνδρας ασιατικής καταγωγής, δεν είναι απλά ένα κτίριο αλλά ένα σχολικό κτίριο, δεν είναι απλά ένα όχημα αλλά ένα τανκ τύπου Leopard II), τότε θα πρέπει να αυξήσουμε και την πολυπλοκότητα. Δηλαδή, το σύστημά μας θα πρέπει (α) να υπολογίζει για κάθε εικόνα πολλά περισσότερα χαρακτηριστικά από δύο, (β) να εκπαιδευτεί με πάρα πολλά δείγματα (δεκάδες χιλιάδες ή και εκατομμύρια) από κάθε είδος εικόνας, και (γ) κατά την εκπαίδευση, μαζί με το κάθε δείγμα, να του δίνουμε και κάθε είδος πληροφορία που μπορεί να του ζητήσουμε αργότερα. Δηλαδή, αν θέλουμε να μπορεί να αναγνωρίσει την ηλικία ενός ανθρώπου, θα πρέπει σε κάθε δείγμα εικόνας ανθρώπου που του έχουμε δώσει να του έχουμε πει και την ηλικιακή κατηγορία στην οποία ανήκει. Αυτό σημαίνει πολλαπλές ετικέτες για κάθε εικόνα.
Στην ουσία, το πόσο «έξυπνο» είναι ένα τέτοιο σύστημα εξαρτάται κυρίως από τρία πράγματα:
1. Πόσα χαρακτηριστικά υπολογίζει για την κάθε εικόνα.
2. Πόσες εικόνες θα χρησιμοποιηθούν για την εκπαίδευσή του.
3. Πόσες ετικέτες (πληροφορία) θα δοθούν κατά την εκπαίδευση για κάθε εικόνα.
Οι δυνατότητες τέτοιων συστημάτων είναι παρόμοιες και στην περίπτωση που η είσοδος είναι ήχος, αντί για εικόνα. Μπορούμε να εκπαιδεύσουμε το σύστημα με δείγματα ήχων ώστε να μπορεί να ξεχωρίσει, για παράδειγμα, μια ομιλία από ένα κελάϊδισμα ή από τον ήχο που κάνει ένα drone. Και πάλι, όσες πιο πολλές ετικέτες του δίνουμε κατά τη λειτουργία εκπαίδευσης για κάθε δείγμα ήχου που χρησιμοποιούμε, τόσα περισσότερα πράγματα θα μπορέσουμε να του ζητήσουμε να αναγνωρίσει αργότερα κατά την κανονική λειτουργία (σε τι γλώσσα είναι η ομιλία, αν μιλάει άνδρας ή γυναίκα, αν αυτός που μιλάει είναι εκνευρισμένος ή χαρούμενος κ.λπ.).
Βέβαια, όσο πιο «έξυπνο» θέλουμε να είναι το σύστημά μας και όσο πιο γρήγορα πρέπει να αποκρίνεται, τόσο:
- πιο πολύ επεξεργαστική ισχύ απαιτεί (εγκαταστάσεις, ενέργεια)
- πιο πολύ αποθηκευτικό χώρο απαιτεί (εγκαταστάσεις, ενέργεια)
Η αύξηση της πολυπλοκότητας που μπορούμε να επιτύχουμε δεν αφορά μόνο το πόσα είδη πληροφορίας μπορεί να αναγνωρίσει το σύστημά μας, αλλά και το πόσο σύνθετη μπορεί να είναι αυτή η πληροφορία. Για παράδειγμα, να αναγνωρίσει ότι μια εικόνα μπορεί να περιλαμβάνει πολλά αντικείμενα, π.χ. ένα τανκ μέσα σε ένα χωράφι από στάχυα. Ή να αναγνωρίσει ότι ένα αρχείο ήχου περιέχει τόσο μια ομιλία όσο και έναν ήχο αυτοκινήτου στο υπόβαθρο.
Α5. Νευρωνικά δίκτυα – Αυτοδίδακτα εργαλεία τεχνητής νοημοσύνης [1]
Αν αυτές είναι οι βασικές αρχές που διέπουν όλα τα συστήματα τεχνητής νοημοσύνης, σε τι διαφέρουν όλα αυτά τα εντυπωσιακά συστήματα τα οποία παρουσιάστηκαν τα τελευταία χρόνια, όπως το ChatGPT, το Dall-E ή τα αυτόνομα οχήματα της Tesla; Για να το απαντήσουμε αυτό, ας δούμε κάποια από τα βασικά χαρακτηριστικά των νέων αυτών συστημάτων:
(α) Η πολυπλοκότητα των σύγχρονων συστημάτων είναι πολύ μεγαλύτερη. Και όπως εξηγήσαμε, αυξημένη πολυπλοκότητα σημαίνει αυξημένες απαιτήσεις σε χώρο και ενέργεια. Δεν είναι τυχαίο ότι η εξάπλωση της χρήσης A.I που έχει ξεκινήσει τα τελευταία χρόνια συνοδεύεται από την ανάγκη δημιουργίας τεράστιων data centers και επιστροφή στην πυρηνική τεχνολογία (π.χ. την ανάπτυξη μικρών αρθρωτών αντιδραστήρων γνωστών ως SMR), ώστε να τροφοδοτηθούν αυτά τα data centers από σταθερή και αδιάλειπτη (24/7) ενέργεια. Διαφορετικά, οι ποσότητες υδρογονανθράκων (λιγνίτης, πετρέλαιο, φυσικό αέριο) που θα έπρεπε να αντληθούν, να μεταφερθούν και να χρησιμοποιηθούν για την παραγωγή ηλεκτρικής ενέργειας θα ήταν τεράστιες, και κάθε διαταραχή στην ενεργειακή αυτή αλυσίδα θα δημιουργούσε πρόβλημα στα data centers. Επίσης, οι τεράστιες υποδομές που απαιτούν σημαίνει ότι τα συστήματα αυτά δεν μπορούν να παραδοθούν ως προϊόν το οποίο ο πελάτης θα εγκαταστήσει και θα χρησιμοποιεί αποκλειστικά πάνω στον υπολογιστή του ή στην εταιρία του, αλλά θα φιλοξενούνται σε κεντρικές εγκαταστάσεις και θα παρέχονται ως online υπηρεσίες στους χρήστες.
(β) Χρησιμοποιούν διαφορετική τεχνολογία. Μέχρι πριν μερικά χρόνια, τα περισσότερα συστήματα τεχνητής νοημοσύνης χρησιμοποιούσαν συγκεκριμένα χαρακτηριστικά για την ανάλυση της εισόδου, τα οποία καθορίζονταν από τους δημιουργούς του συστήματος, και ήταν διάφανος ο τρόπος με τον οποίο αποφασιζόταν η έξοδος μετά την εκπαίδευση. Στα σύγχρονα συστήματα τα χαρακτηριστικά ανάλυσης της εισόδου δεν είναι αυστηρά καθορισμένα από τους δημιουργούς του. Δίνονται κάποιες γενικές κατευθύνσεις κατά τον σχεδιασμό, αλλά πέρα από αυτές κανείς δεν μπορεί να εξηγήσει ποια ακριβώς μοτίβα έχουν ανιχνευθεί κατά την εκπαίδευση και πώς αυτά τα μοτίβα επηρεάζουν την έξοδο μετά από αυτή. Πέρα από μια κατανόηση της γενικότερης δομής, η υπόλοιπη λειτουργία παραμένει ένα, όπως χαρακτηρίζεται, «μαύρο κουτί» (το οποίο αποτελεί μια μεταφορική έννοια, που χρησιμοποιείται για να περιγράψει συστήματα των οποίων οι εσωτερικές διαδικασίες λήψης αποφάσεων παραμένουν άγνωστες, ή είναι υπερβολικά περίπλοκες για να αναλυθούν από τον άνθρωπο). Αυτό έχει να κάνει με τη νέα αρχιτεκτονική των συστημάτων που χρησιμοποιείται, η οποία είναι γνωστή ως «νευρωνικά δίκτυα» γιατί είναι εμπνευσμένη απο τη λειτουργία των νευρώνων του ανθρώπινου εγκεφάλου.
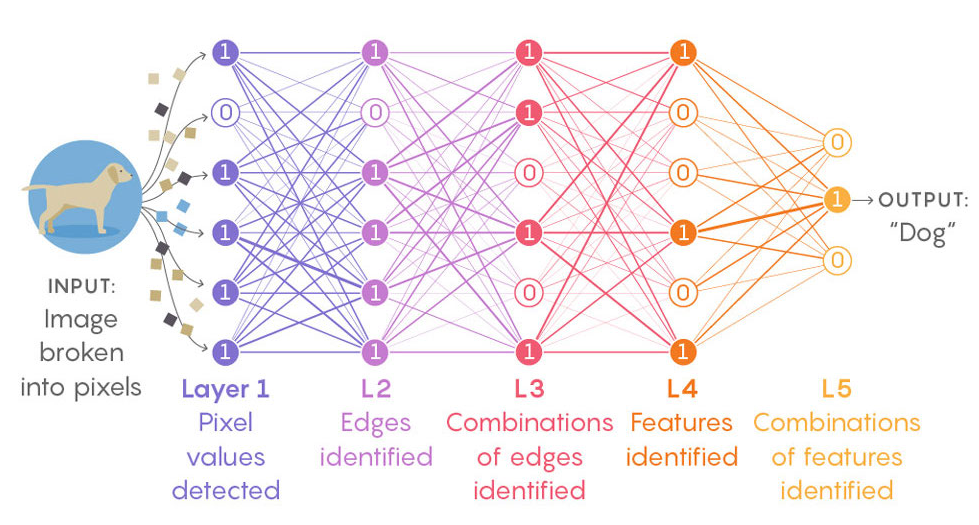
Πηγή: https://medium.com/coinmonks/advancements-of-convolutional-neural-networks-part-1-introduction-and-main-operations-5d12f35b28d4
(γ) Τα συστήματα αυτά επιτρέπουν τη συνέχεια της εκπαίδευσής τους (αν και σε πολύ μικρότερο βαθμό) κατά την κανονική λειτουργία. Κατά το διάστημα αυτό, χρησιμοποιούν ως εκπαιδευτικό υλικό είτε την πληροφορία που παρέχει ο χρήστης κατά την αλληλεπίδραση με το σύστημα, είτε πληροφορία που βρίσκουν στο διαδίκτυο καθώς προσπαθούν να εξυπηρετήσουν αιτήματα του χρήστη. Αυτό σημαίνει ότι τα νέα συστήματα τεχνητής νοημοσύνης μπορεί να μεταβάλλονται κατά τη χρήση τους.
(δ) Τα περισσότερα από αυτά τα συστήματα χρησιμοποιούν εσκεμμένα ένα μικρό βαθμό τυχαιότητας στην έξοδο ώστε να εμφανίζουν κάποια πρωτοτυπία. Για παράδειγμα, αν δύο άτομα κάνουν την ίδια ερώτηση στο ChatGPT είναι πολύ πιθανόν να πάρουν διαφορετική απάντηση κάθε φορά. Όχι τόσο στο νόημα ή το περιεχόμενο, όσο στον τρόπο με τον οποίο θα εκφραστεί η απάντηση αυτή. Το ίδιο και αν δύο χρήστες ζητήσουν από το Dall-E να τους φτιάξει μια εικόνα χρησιμοποιώντας την ίδια περιγραφή. Οι δύο εικόνες δεν θα είναι ίδιες.
Οι δύο πιο γνωστές κατηγορίες των σύγχρονων εργαλείων τεχνητής νοημοσύνης που χρησιμοποιούν νευρωνικά δίκτυα είναι τα Μεγάλα Γλωσσικά Μοντέλα (LLMs) και οι γεννήτριες εικόνων (Image Generators). Παρόλο που και τα δύο έχουν τις ίδιες βασικές αρχές, έχουν αρκετά διαφορετικό τρόπο λειτουργίας.
Τα Μεγάλα Γλωσσικά Μοντέλα (Large Language Models ή LLMs) [1][2][3][4][5]
Τα LLMs είναι στην ουσία προγράμματα τα οποία αναλύουν τη δομή κειμένων και εντοπίζουν μοτίβα μέσα σε αυτή. Για παράδειγμα, ποια λέξη βρίσκεται νοηματικά κοντά σε μια άλλη, ποια λέξη συνήθως ακολουθεί ή προηγείται μιας άλλης, ποια είναι η πιθανότητα μια λέξη να εμφανιστεί σε ένα κείμενο όταν στο ίδιο κείμενο εμφανίζονται και κάποιες άλλες συγκεκριμένες λέξεις κ.λπ. Όλα αυτά εξάγονται με μαθηματική ανάλυση του κειμένου. Η πιο γνωστή μας μορφή ενός LLM είναι τα διάφορα chat bots, όπως το ChatGPT της OpenAI, το Gemini της Google, το Grok της Tesla, το κινέζικο DeepSeek και άλλα πολλά. Για την ώρα, τα περισσότερα από αυτά προσφέρουν δωρεάν πρόσβαση με κάποιο περιορισμό στον αριθμό των ερωτήσεων που υποβάλλουμε ανά ώρα ή ανά μέρα.
Ο τρόπος με τον οποίο χτίζουν την απάντηση είναι το να προβλέπουν κάθε φορά, για τη συγκεκριμένη ερώτηση (είσοδο), ποια είναι η πιθανότητα κάθε λέξης να είναι η επόμενη. Αφού υπολογίσουν αυτή την πιθανότητα για όλες τις λέξεις του λεξιλογίου, επιλέγουν την πιο πιθανή (ή μία από τις πιο πιθανές) και την τοποθετούν στην απάντηση (έξοδο). Η έξοδος χτίζεται σταδιακά, λέξη-λέξη. Για κάθε λέξη που έχει επιλεχθεί, η νέα είσοδος είναι «ερώτηση + προσωρινή απάντηση»· και με βάση αυτή υπολογίζεται η νέα λέξη που έχει τη μεγαλύτερη πιθανότητα να ακολουθεί. Η λέξη αυτή προστίθεται στην προσωρινή απάντηση και η ίδια διαδικασία επαναλαμβάνεται. Οι πιθανότητες των λέξεων υπολογίζονται με βάση το κείμενο εισόδου και τα μοτίβα που έχουν ανακαλυφθεί σε διάφορα κείμενα (βιβλία, άρθρα, συνομιλίες κ.λπ.) τα οποία χρησιμοποιήθηκαν στην εκπαίδευση του συστήματος.
Κάθε λέξη που υπάρχει στην ερώτηση, καθώς και η θέση την οποία κατέχει μέσα στο κείμενο της ερώτησης, παίζει ρόλο στη διαμόρφωση της απάντησης. Και αυτό γιατί οι λέξεις και η θέση τους επηρεάζουν τα αποτελέσματα της στατιστικής ανάλυσης που γίνεται κατά τη διάρκεια της εκπαίδευσης. Και αυτό γίνεται εσκεμμένα. Η λέξη "οδηγός" στην πρόταση "ένας οδηγός ταξί" έχει εντελώς διαφορετικό νόημα από ότι στην πρόταση "οδηγός ταξιδιού για την Ελλάδα" και έτσι, ενώ η αρχική μαθηματική αναπαράσταση που χρησιμοποιεί το LLM για την λέξη "οδηγός" είναι η ίδια και στις δύο περιπτώσεις, η αναπαράσταση αυτή θα αλλάξει πολύ κατά τη διάρκεια της ανάλυσης. Η τοπική πληροφορία (οι λέξεις που προηγούνται ή έπονται μέσα στην ίδια πρόταση) επηρεάζουν το νόημα της λέξης. Το ίδιο συμβαίνει και με τη μη-τοπική πληροφορία. Το συνολικό κείμενο της εισόδου επηρεάζει το νόημα μιας λέξης μέσα σε μια συγκεκριμένα πρόταση (π.χ. η λέξη «υποβρύχιο» μέσα σε ένα κείμενο που μιλάει για έναν πόλεμο έχει εντελώς διαφορετική σημασία από την λέξη «υποβρύχιο» σε ένα κείμενο που μιλάει για παραδοσιακά γλυκίσματα). Έτσι, η πιθανότητα υπολογισμού της επόμενης λέξης κατά το χτίσιμο της απάντησης επηρεάζεται τόσο από τις λέξεις που υπάρχουν στην είσοδο, όσο και με ποια σειρά, συχνότητα ή συνδυασμούς εμφανίζονται, σε ποια γλώσσα ανήκουν, και πολλά άλλα.
* για κάποιες παραπάνω πληροφορίες πάνω στην αρχιτεκτονική των LLMs, δείτε εδώ
Οι Γεννήτριες Εικόνων (Image Generators) [6][7][8][9][10]
Τέτοια συστήματα χρησιμοποιούνται συχνά σε εργαλεία μετατροπής κειμένου σε εικόνα (π.χ. Midjourney, Stable Diffusion, Nano Banana, Adobe Firefly) ή κειμένου σε βίντεο (π.χ. CogVideo, Google's Imagen). Τα εργαλεία αυτά είναι νευρωνικά δίκτυα που χρησιμοποιούν εντελώς διαφορετικές τεχνικές από τα LLMs για να κατασκευάσουν εικόνες υψηλής ποιότητας με βάση την περιγραφή που δίνουμε. Η πιο διαδεδομένη από αυτές τις τεχνικές ονομάζεται «διάχυση θορύβου» (Noise Diffusion) και προέρχεται από τη θερμοδυναμική. Ας δούμε λίγο τη διαδικασία.
Έστω ότι έχουμε μια εικόνα ενός πλοίου. Σε κάθε βήμα της διαδικασίας προσθέτουμε τυχαίο «θόρυβο» στην εικόνα (ψηφιακά «παράσιτα», όπως το "χιόνι" που έβγαζαν οι παλιές τηλεοράσεις όταν δεν είχαν σήμα) έτσι ώστε η εικόνα να γίνει λίγο πιο δυσδιάκριτη, και συνεχίζουμε μέχρι αυτό που απεικονιζόταν να χαθεί, και να έχουμε μια εικόνα μόνο με θόρυβο. Κάθε φορά που προσθέτουμε θόρυβο, εκπαιδεύουμε το νευρωνικό μας δίκτυο ώστε, με βάση την εικόνα εισόδου και το αποτέλεσμα στην έξοδο, να εκτιμήσει τον θόρυβο που έχει προστεθεί. Η διαδικασία προσθήκης του θορύβου λαμβάνει υπόψη και την περιγραφή της κάθε εικόνας (δηλαδή ένα κείμενο που περιγράφει τι δείχνει η εικόνα). Μετά την εκπαίδευση, το νευρωνικό αυτό δίκτυο μπορεί να χρησιμοποιηθεί ώστε, ξεκινώντας από μια εικόνα που περιέχει μόνο θόρυβο, να αφαιρεί θόρυβο λίγο-λίγο μέχρι να πάρουμε μια εικόνα σύμφωνα με την περιγραφή που έχουμε δώσει. Όπως στην εκπαίδευση ο τρόπος με τον οποίο προσθέτουμε θόρυβο επηρεάζεται από την περιγραφή της εικόνας, έτσι και στην κανονική λειτουργία, ο τρόπος με τον οποίο αφαιρούμε θόρυβο επηρεάζεται και πάλι από την περιγραφή της εικόνας.

Έτσι, η περιγραφή που δίνουμε επηρεάζει το τελικό αποτέλεσμα και θα καταλήξουμε σε μια εικόνα με χαρακτηριστικά παρόμοια με αυτά που εξάχθηκαν από εικόνες με αντίστοιχες περιγραφές.
Όπως και στην αναγνώριση των χαρακτηριστικών του κειμένου, και εδώ, κατά την εκπαίδευση, το νευρωνικό δίκτυο ανιχνεύει στην εικόνα διάφορα χαρακτηριστικά που συναντά, ξεκινώντας από τοπικά χαρακτηριστικά (ακμές, γωνίες, καμπύλες, διαβαθμίσεις χρώματος, κ.λπ.). Στα επόμενα στάδια χρησιμοποιούνται τα ευρήματα των προηγούμενων για να ανιχνευτούν πιο σύνθετα και μη-τοπικά χαρακτηριστικά (γενική αποτύπωση σχημάτων και υφών) και στην συνέχεια να καταλήξει στην αναγνώριση περιοχών (π.χ. την υφή/σχέδιο ενός χαλιού, ενός χωραφιού με στάχυα ή μιας θάλασσας), απλών αντικειμένων (το χαλί σαν αντικείμενο πάνω στο πάτωμα, ένα σκιάχτρο μέσα στο χωράφι, ένα πλοίο μέσα στη θάλασσα), και πιο πολύπλοκων σχημάτων όπως η δομή πιο σύνθετων τμημάτων (π.χ. στη δομή του σώματος ενός σκύλου ανιχνεύεται η συνήθης απόσταση της ουράς από το κεφάλι, η θέση του τριχώματος σε σχέση με το υπόλοιπο σώμα κ.λπ.).
Κάθε εικόνα αναπαρίσταται από μια ομάδα αριθμών (διάνυσμα), όπου κάθε αριθμός είναι η τιμή ενός χαρακτηριστικού της εικόνας (όπως στο παράδειγμά μας νωρίτερα που εξετάζαμε πόσο λεία είναι η υφή ή πόσο έντονα είναι τα χρώματα). Σε εικόνες που είναι παρόμοιες, πολλές από τις τιμές των χαρακτηριστικών αυτών θα είναι αριθμητικά κοντά. Επίσης, υπάρχουν τεχνικές οι οποίες μας επιτρέπουν να συσχετίσουμε συγκεκριμένες περιοχές τιμών με συγκεκριμένες κειμενικές περιγραφές. Όπως στο παράδειγμά μας νωρίτερα, όπου χωρίσαμε τις τιμές των 2 χαρακτηριστικών με μια ευθεία και αντιστοιχίσαμε κάθε περιοχή με μια ετικέτα. Η διαφορά εδώ είναι ότι τα χαρακτηριστικά δεν είναι 2, αλλά πολύ περισσότερα (π.χ. 2000). Η ανακάλυψη τέτοιων μοτίβων που συνδέουν την περιοχή στην οποία βρίσκονται οι τιμές των χαρακτηριστικών με την περιγραφή της εικόνας μας επιτρέπουν να μετακινούμαστε από μία συγκεκριμένη περιοχή σε μία άλλη κάθε φορά που μια συγκεκριμένη λέξη προστίθεται ή αφαιρείται από μια κειμενική περιγραφή. Έτσι, όταν δώσουμε μια συγκεκριμένη περιγραφή ως είσοδο, το σύστημα εντοπίζει την περιοχή που αντιστοιχεί σε εικόνες με αντίστοιχη περιγραφή, επιλέγει (με σχεδόν τυχαίο τρόπο) ένα σημείο της περιοχής αυτής και συνθέτει μια εικόνα με αυτές τις τιμές χαρακτηριστικών.
Γιατί με την ίδια περιγραφή δεν μας δίνει πάντα την ίδια εικόνα, ούτε μας δίνει κάποια από τις εικόνες εκπαίδευσης, ακόμα και αν η περιγραφή είναι ίδια;
Αυτό οφείλεται σε δύο λόγους. Πρώτον, επειδή κάθε περιγραφή δεν αντιστοιχεί σε συγκεκριμένες τιμές των χαρακτηριστικών αλλά σε μια περιοχή τιμών. Η τυχαία επιλογή ενός σημείου (διαφορετικού κάθε φορά) στην περιοχή αυτή για κάθε χαρακτηριστικό σπάνια θα συμπίπτει με τις τιμές κάποιας από τις εικόνες που χρησιμοποιήθηκαν στην εκπαίδευση. Δεύτερον, κάθε σημείο της περιοχής που αντιστοιχεί σε μια εικόνα εκπαίδευσης δεν αναπαριστά με ακρίβεια την εικόνα αυτή, αλλά κάποιες ιδιότητές της. Οπότε, αν συνθέσουμε μια εικόνα ακόμα και με ίδιες τιμές χαρακτηριστικών, δεν θα είναι ακριβώς ίδια.
Πώς το εργαλείο δουλεύει με περιγραφές εικόνων για τις οποίες δεν έχει εκπαιδευτεί;
Η συσχέτιση της εικόνας με το κείμενο μας δίνει και ένα άλλο πλεονέκτημα. Για παράδειγμα, έστω ότι το νευρωνικό δίκτυο έχει εκπαιδευτεί με εικόνες που έχουν περιγραφεί ως «αυτοκίνητο», «σκύλος», «κτίριο», «αστυνομικός», «αστυνομικός μπροστά από κτίριο». Αν του ζητήσουμε να μας φτιάξει μία εικόνα με την περιγραφή «σκύλος μπροστά από αυτοκίνητο» θα μπορέσει να το κάνει, παρόλο που δεν έχει ξανασυναντήσει τέτοια εικόνα στην εκπαίδευση, γιατί:
(α) ξέρει πως να χτίσει τη μορφή ενός σκύλου
(β) ξέρει πως να χτίσει τη μορφή ενός αυτοκινήτου
(γ) έχει μια ιδέα για το πως να χτίσει την εικόνα όπου το Α είναι μπροστά από το Β (πού πρέπει να τοποθετήσει το Α και πού το Β, και πόσο μεγάλο πρέπει να είναι το ένα σε σχέση με το άλλο)
Οπότε, θα ανασύρει την πληροφορία για το κάθε ένα από τα (α), (β) και (γ) και θα τη συνδυάσει ώστε να χτίσει την επιθυμητή εικόνα.
Άρα, για να υποστηρίξουμε την παραγωγή εικόνων από αναλυτική περιγραφή, θα πρέπει να έχουμε εκπαιδεύσει το νευρωνικό δίκτυο με όσα περισσότερα νοήματα γίνεται. Με άλλα λόγια, θέλουμε πολλές εικόνες και πλούσιες περιγραφές για κάθε εικόνα ώστε να μπορέσει να συσχετίσει σωστά την κάθε λέξη με τα σωστά χαρακτηριστικά.
A6. Περιορισμοί στη λειτουργία των συστημάτων A.I
Παραισθήσεις [11][12][13][14]
Ένα πρόγραμμα δεν μπορεί να αναγνωρίσει τίποτα για το οποίο δεν το έχουμε εκπαιδεύσει. Στο απλό σύστημα που περιγράψαμε αρχικά (με τα μήλα και τα πορτοκάλια), όσες εικόνες από αχλάδια και αν του δείξουμε κατά την κανονική λειτουργία, δεν θα χρησιμοποιήσει ποτέ την ετικέτα "αχλάδια".
Είναι χαρακτηριστικό αυτό που είχε συμβεί το 2015 με την υπηρεσία Google Photos, η οποία έδωσε την περιγραφή «Γορίλες» σε μια φωτογραφία (σέλφι) δύο μαύρων αμερικανών από την Αϊτή, μόνο και μόνο επειδή οι εικόνες που είχαν χρησιμοποιηθεί για την εκπαίδευση της υπηρεσίας δεν περιείχαν μαύρους. Και επειδή η επανεκπαίδευση ενός τέτοιου συστήματος είναι χρονοβόρα και κοστοβόρα διαδικασία, το αποτέλεσμα ήταν οι υπεύθυνοι της Google να απομακρύνουν τη λέξη «Γορίλας» από όλες τις περιγραφές που έδινε αυτόματα το Google Photos (ακόμα και φωτογραφιών που έδειχναν γορίλες) για χρόνια.
Το ίδιο ισχύει και για ένα σύστημα που φτιάχνει εικόνες με βάση μια περιγραφή. Για παράδειγμα, εάν έχουμε χρησιμοποιήσει για εκπαίδευση 10.000 εικόνες θάλασσας και όλες είχαν την περιγραφή «θάλασσα», τότε, αν του δώσουμε την περιγραφή «γαλαζοπράσινη θάλασσα», δεν θα μπορέσει να μας κατασκευάσει αυτό που θέλουμε. Πιθανό να κατασκευάσει την εικόνα μιας βαθιά μπλε θάλασσας γιατί δεν έχει αποθηκεύσει τα χαρακτηριστικά της έννοιας «γαλαζοπράσινος». Αν όμως έχει εκπαιδευτεί και με 10.000 εικόνες από φορέματα, και 300 από αυτές έχουν την περιγραφή «γαλαζοπράσινο φόρεμα», τότε το σύστημα θα έχει διακρίνει τόσο το ποιο χαρακτηριστικό αυτών των εικόνων σχετίζεται με τη λέξη «γαλαζοπράσινο», όσο και σε ποια περιοχή βρίσκονται οι τιμές του όταν χρησιμοποιείται αυτή η λέξη. Έτσι, θα μπορέσει να εφαρμόσει αυτό το χαρακτηριστικό και να μας δώσει μια καλή προσέγγιση μιας γαλαζοπράσινης θάλασσας.
Οι έξοδοι/απαντήσεις που δίνει ένα εργαλείο τεχνητής νοημοσύνης σε περιπτώσεις όπως αυτές που περιγράψαμε παραπάνω (να δίνει την περιγραφή «μήλα» όταν του δείχνουμε μια εικόνα με αχλάδια ή να μας δίνει μια εικόνα με βαθιά μπλε θάλασσα όταν εμείς του έχουμε ζητήσει μια γαλαζοπράσινη θάλασσα) ονομάζονται «παραισθήσεις»· και μπορούν να συμβούν σε όλα τα συστήματα τεχνητής νοημοσύνης, από τα πιο απλά μέχρι τα πιο σύνθετα. Όμως, η εμφάνιση παραισθήσεων στα νεότερα συστήματα, που βασίζονται σε νευρωνικά δίκτυα, είναι πιο συχνή και απροσδόκητη γιατί έχουν πιο γενική χρήση από τα παλιότερα· και σαν χρήστες περιμένουμε από αυτά να κάνουν εργασίες τις οποίες δεν μπορούν πάντα να διεκπεραιώσουν με επιτυχία.
Το είδος των παραισθήσεων που περιγράψαμε παραπάνω είναι μόνο ένα από τα πολλά που μπορούν να εμφανιστούν στο πλαίσιο της λειτουργίας ενός LLM, όπως:
(1) Να δώσει μια απάντηση η οποία έρχεται σε αντίθεση με μία από τις προηγούμενες απαντήσεις του.
(2) Να δώσει μια απάντηση η οποία κάνει το αντίθετο από αυτό που του ζητήσαμε.
(3) Να δώσει μια απάντηση η οποία είναι λάθος (με βάση τα γεγονότα).
(4) Να δώσει μια απάντηση η οποία δεν έχει νόημα σε σχέση με αυτό που το ρωτήσαμε.
Μερικοί επιπλέον λόγοι για τους οποίους συμβαίνουν αυτές οι παραισθήσεις είναι:
(α) εκπαίδευση με κακής ποιότητας δεδομένα (περιέχουν λάθη, ανακρίβειες, ψέματα κ.λπ.). Αυτό είναι κάτι που ένα LLM δεν μπορεί να καταλάβει μιας και τα χρησιμοποιεί απλά και μόνο για να κάνει γενικεύσεις (να αναγνωρίσει μοτίβα).
(β) To LLM προσπαθεί να είναι δημιουργικό και πρωτότυπο. Πολλές φορές η διαθέσιμη πληροφορία σχετικά με την ερώτηση δεν είναι επαρκής, αλλά παρ’ όλ’ αυτά το LLM προτιμά να «μαντέψει» (δηλαδή, να επιλέξει μία έξοδο με χαμηλή πιθανότητα) αντί να παραδεχθεί ότι δεν είναι βέβαιο (δηλαδή, να επιλέξει να μην απαντήσει). Οι δημιουργοί των LLMs έχουν εισάγει αυτή τη μορφή «δημιουργικότητας» για δύο λόγους. Ο πρώτος είναι ώστε αυτά να παρουσιάζουν καλές επιδόσεις όταν λαμβάνουν μέρος σε διάφορα τεστ. Ως γνωστόν, στα τεστ, όταν δεν ξέρεις την απάντηση, το να μαντέψεις την απάντηση αντί να μην απαντήσεις μπορεί να σε οδηγήσει σε καλύτερα αποτελέσματα, αλλά ποτέ σε χειρότερα. Ο δεύτερος είναι για να παρουσιάζουν μια ποικιλία, μια πρωτοτυπία στον τρόπο που εκφράζονται. Αυτή η δημιουργικότητα χρησιμοποιείται ακόμα και όταν υπάρχει επαρκής πληροφορία. Ακόμα και τότε, μερικές φορές, τα LLMs δεν επιλέγουν πάντα ως επόμενη λέξη την πιο πιθανή αλλά μία από τις πιο πιθανές. Όταν όμως, αγνοώντας την πιο πιθανή λέξη, οι επόμενες λέξεις έχουν πολύ μικρότερη πιθανότητα, τότε μπορεί να οδηγηθούμε σε μια δήλωση η οποία δεν στέκει ή είναι ψεύτικη. Αυτή η δημιουργικότητα είναι επιθυμητή, και δεν είναι κάποιο σχεδιαστικό λάθος.
Βέβαια, τις περισσότερες φορές, όταν το LLM δεν βρίσκει επαρκή πληροφορία στα δεδομένα του, προσπαθεί να εντοπίσει επιπλέον πληροφορία στο διαδίκτυο. Αν και πάλι δεν βρει ικανοποιητική ποσότητα πληροφορίας, μπορεί να ενημερώσει τον χρήστη ότι δεν μπορεί να απαντήσει, ή μπορεί να δοκιμάσει να μαντέψει την απάντηση. Η τελευταία επιλογή, που συχνά οδηγεί σε «παραισθήσεις», δεν μπορεί να αποκλειστεί. Μερικά LLMs προσφέρουν τη δυνατότητα στον χρήστη να αυξομειώσει τα επίπεδα δημιουργικότητας που χρησιμοποιούν (συνήθως αναφέρονται σε αυτά ως «θερμοκρασία»— ένας όρος δανεισμένος από τη θερμοδυναμική, όπου η αύξηση της θερμοκρασίας αυξάνει την ένταση και την τυχαιότητα κίνησης των σωματιδίων).
(γ) Το κείμενο εισόδου μπορεί να είναι ασαφές ή αντιφατικό, και αυτό μπορεί να μπερδέψει το LLM. Για παράδειγμα, το LLM μπορεί να υποθέσει ότι το πλαίσιο συζήτησης είναι διαφορετικό από αυτό που εννοούμε. Όπως όλοι ξέρουμε στον πραγματικό κόσμο οι πιγκουίνοι δεν μιλάνε. Αν όμως μιλάμε για την ταινία «Μαδαγασκάρη», τότε οι πιγκουίνοι μιλάνε μια χαρά.
Το (γ) μπορεί να αντιμετωπιστεί από έμπειρους χρήστες χτίζοντας το ερώτημά τους με αρκετή σαφήνεια. Το (β), δηλαδή οι παραισθήσεις λόγω δημιουργικότητας, μπορεί να ελαττωθεί μειώνοντας τη «θερμοκρασία» του LLM (τον βαθμό τυχαιότητας που χρησιμοποιεί) ανάλογα με το πόσο ακριβής ή δημιουργική θέλουμε να είναι η απάντηση. To πρόβλημα ξεκινά όταν ασχοληθούμε με το (α) για να λύσουμε παραισθήσεις τύπου (3) (βλ. παραπάνω). Επειδή τα LLMs εκπαιδεύονται με τέτοιο τρόπο ώστε να αποφασίζουν ότι η σωστή ή η κυρίαρχη απάντηση σε ένα θέμα είναι μία, η εξασφάλιση μιας ποιοτικής επιλογής απαιτεί τη διάκριση μεταξύ πηγών που είναι σωστές/αξιόπιστες και πηγών που είναι λάθος/αναξιόπιστες, ή τη διάκριση μεταξύ του βαθμού αξιοπιστίας των πηγών. Άρα, οι δημιουργοί ενός LLM αναγκάζονται να πάρουν θέση πάνω στην αξιοπιστία των πηγών. Και ενώ το αντίκτυπο τέτοιων αποφάσεων μπορεί να μην είναι τόσο έντονο σε θέματα που αφορούν γεγονότα, είναι αρκετά μεγάλο σε υποκειμενικά θέματα στα οποία οι διάφορες θέσεις αποτελούν απόψεις και γνώμες. Επίσης, ας μην ξεχνάμε ότι ο χρήστης μπορεί να κατευθύνει το LLM ώστε να συμπεριλάβει συγκεκριμένες πηγές χαμηλής ποιότητας στην απάντησή του, και ότι τα LLMs χρησιμοποιούν τις ίδιες τους τις απαντήσεις για να επεκτείνουν την εκπαίδευσή τους. Η ποιότητα των απαντήσεών τους (και άρα ο τρόπος με τον οποίο θα χρησιμοποιηθούν για εκπαίδευση) κρίνεται από συστήματα των ίδιων των LLMs. Αυτό μπορεί να οδηγήσει στη σταδιακή υποβάθμιση της ποιότητας της πληροφορίας που παρέχει το LLM, σε έντονες τάσεις του LLM να υποστηρίζει μια συγκεκριμένη θέση πάνω σε κάποια θέματα κ.λπ. Οι λύσεις εδώ δεν είναι πολλές. Απαιτείται είτε ανθρώπινη παρέμβαση που θα καθοδηγεί προς συγκεκριμένες κατευθύνσεις (τις «σωστές»), είτε αξιολόγηση των πηγών, είτε ενσωμάτωση συγκεκριμένων θέσεων πάνω σε συγκεκριμένα θέματα. Κάπως έτσι καταλήγουμε στο ερώτημα «ποιος αποφασίζει τι είναι αλήθεια ή τι είναι λογικό, τι είναι σωστό και τι όχι;»· και, κατά συνέπεια, πώς θα φιλτράρεται η πληροφορία που αναζητά κάποιος στο διαδίκτυο. Θα μπορεί ο καθένας να δίνει τις δικές του κατευθύνσεις και κανόνες αναζήτησης πληροφορίας στο LLM που χρησιμοποιεί; Αυτό θα ήταν δύσκολο, γιατί, όπως έχουμε εξηγήσει, τα LLM έχουν αποκτήσει τις γενικές τους γνώσεις ήδη πριν τα χρησιμοποιήσουμε, και επηρεάζονται από όλους αυτούς που τα χρησιμοποιούν. Θα επανέλθουμε στο θέμα αυτό λίγο παρακάτω όταν θα δούμε το ζήτημα της λογοκρισίας.
Εξοικονόμηση ενέργειας [15][16][17][18][19][20][21][22][23][24]
Όταν ένα LLM δέχεται μια ερώτηση η οποία δεν είναι συνηθισμένη, αναγκάζεται να ψάξει μεγάλο μέρος του νευρωνικού δικτύου για να συνθέσει μια σωστή απάντηση. Αυτό είναι ιδιαίτερα ενεργοβόρο. Για να μειώσει την κατανάλωση ενέργειας κάνει μια προσπάθεια να μαντέψει σε ποιο τμήμα του νευρωνικού δικτύου είναι πιο πιθανό να βρει την απάντηση, και στη συνέχεια αποκλείει τα υπόλοιπα τμήματα (π.χ. ένα 80% του δικτύου) από την αναζήτηση και ψάχνει μόνο σε αυτό. Το πρόβλημα είναι ότι για ερωτήσεις που δεν είναι συνηθισμένες, υπάρχει σημαντική πιθανότητα η σωστή απάντηση (ή μέρος αυτής) να βρίσκεται στο αποκλεισμένο τμήμα, και έτσι η απάντηση που θα επιστρέψει το LLM να είναι λάθος, ελλιπής ή να μην βγάζει νόημα (παραισθήσεις). Είναι όμως τόσο μεγάλες οι απαιτήσεις ενέργειας των συστημάτων A.I που αναγκαζόμαστε να κάνουμε τέτοιες περικοπές;
Τα τυπικά data centers που χρησιμοποιούνται για υπηρεσίες A.I ανήκουν στην κατηγορία Hyperscale, φιλοξενούν δεκάδες χιλιάδες σέρβερς, με απαιτούμενη ισχύ λειτουργίας από μερικές εκατοντάδες MW (δηλαδή, όση ισχύ καταναλώνουν μερικές εκατοντάδες χιλιάδες νοικοκυριά) έως μερικά GW. Μόνο στα LLMs υποβάλλονται δισεκατομμύρια ερωτήματα κάθε μέρα, από απλούς πολίτες μέχρι επαγγελματίες. Οι επενδύσεις σε τέτοια data centers είναι της τάξης των εκατοντάδων δισεκατομμυρίων. Η κατανάλωση ενέργειας από τα data centers ήταν το 1.5% της παγκόσμιας κατανάλωσης ηλεκτρικής ενέργειας για το 2024 και αναμένεται να φτάσει το 3% μέχρι το 2030, δεδομένου ότι οι ανάγκες των data centers αναμένεται να τριπλασιαστούν (45% της κατανάλωσης από τις ΗΠΑ, 25% από την Κίνα, 15% από την Ευρώπη). Αξίζει να σημειωθεί ότι το μεγαλύτερο μέρος της κατανάλωσης δεν οφείλεται στη λειτουργία των servers, αλλά στην ψύξη τους. Μάλιστα, επειδή ο κλιματισμός δεν φαίνεται να είναι ικανοποιητική μέθοδος ψύξης για τα μοντέρνα και τεράστια data centers, αυτά χρησιμοποιούν υδρόψυξη. Το νερό που χρησιμοποιείται είναι κατά βάση γλυκό νερό και, κατά τη διαδικασία της ψύξης, περίπου το 80% του νερού απελευθερώνεται προς το περιβάλλον, είτε ως θερμό νερό είτε μέσω εξάτμισης. Στο παρακάτω διάγραμμα φαίνεται μια εκτίμηση για το πώς περιμένουμε να αυξηθούν οι ενεργειακές ανάγκες για τη λειτουργία του ίντερνετ μέχρι το 2050.
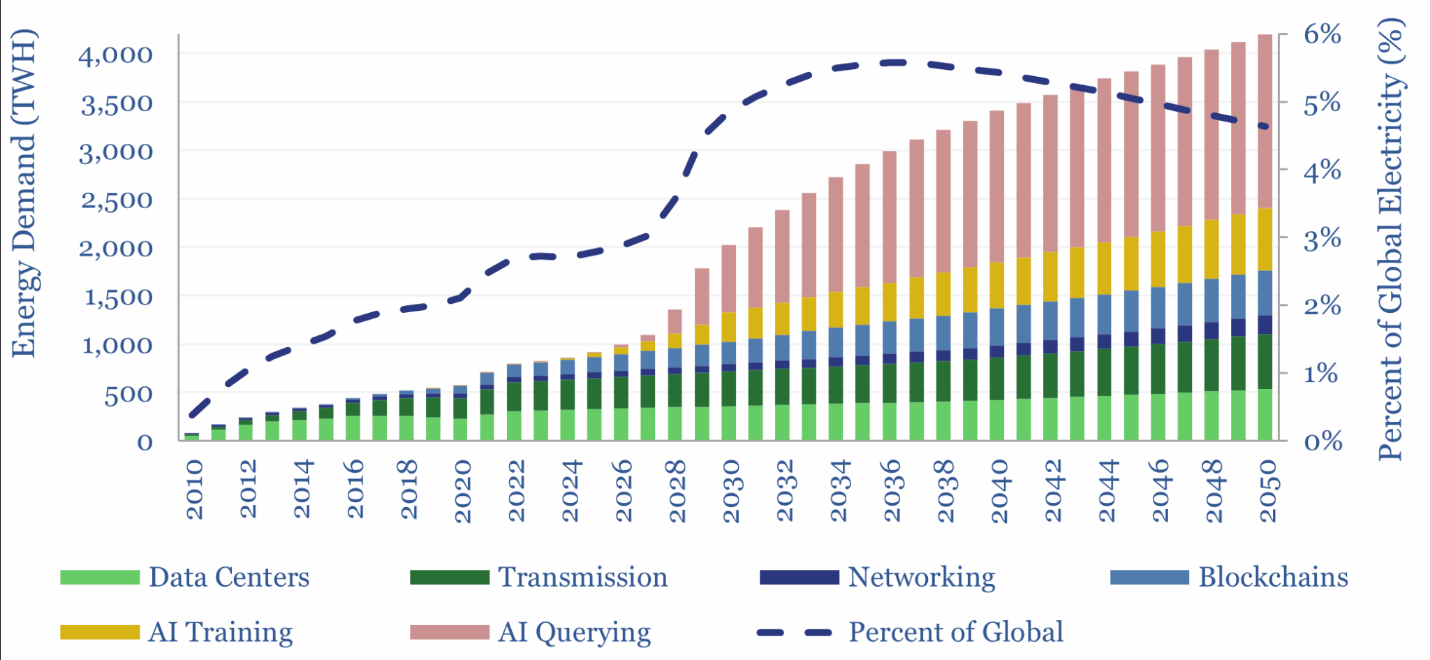
Πρόβλεψη ενεργειακών απαιτήσεων για την λειτουργία του ιντερνετ [17]
Η επιβάρυνση που επιφέρουν τα τεράστια data centers στο περιβάλλον αλλά και στις τοπικές κοινωνίες είναι πολύ μεγάλη: ηχορύπανση και μόλυνση του αέρα από εξωτερικές γεννήτριες, εκτροπές ποταμών για την παραγωγή υδροηλεκτρικής ενέργειας, άντληση γεωθερμικής ενέργειας με ρυθμούς μεγαλύτερους από τον ρυθμό φυσικής αναπλήρωσής της και διατάραξη της λειτουργίας των τοπικών θαλάσσιων οικοσυστημάτων (νεκρές ζώνες, διατάραξη των μεταναστευτικών ροών κ.ά.) από την απόρριψη του ζεστού νερού που έχει χρησιμοποιηθεί στα συστήματα ψύξης. Παράλληλα, το οικονομικό όφελος της τοπικής κοινωνίας είναι σχεδόν ανύπαρκτο, μιας και τα data centers κατασκευάζονται από εξειδικευμένο προσωπικό που συνήθως έρχεται από το εξωτερικό (μόνο για όσο διαρκεί η κατασκευή) και κατά τη λειτουργία τους απαιτούν ελάχιστα άτομα (π.χ. 50 άτομα) ενώ καταναλώνουν ενέργεια όσο πολλές δεκάδες χιλιάδες νοικοκυριά. Και σαν να μην έφταναν αυτά, η ανάγκη για τεράστιες ποσότητες νερού στερεί αυτό το βασικό αγαθό από τις καλλιέργειες, ενώ οι τιμές ρεύματος στην περιοχή οδηγούνται στα ύψη.
Επιπλέον, η σύνδεση των data centers με το ηλεκτρικό δίκτυο δημιουργεί παραμορφώσεις στην τάση και τη συχνότητα της μεταφερόμενης ηλεκτρικής ενέργειας, εξαιτίας του τρόπου σύνδεσης των data centers με το δίκτυο που περιλαμβάνει UPS, ειδικούς μετασχηματιστές και άλλα συστήματα. Τα συστήματα αυτά είναι απαραίτητα μιας και οι servers των data centers δεν καταναλώνουν εναλλασσόμενο ρεύμα αλλά σταθερό, και μάλιστα με συγκεκριμένο τρόπο. Οι παραμορφώσεις αυτές «καταπονούν» τις ηλεκτρικές συσκευές που συνδέονται πάνω στο δίκτυο αυτό, μειώνοντας την απόδοσή τους και τον χρόνο ζωής τους· ιδιαίτερα ηλεκτρικές συσκευές που χρησιμοποιούν κινητήρες (π.χ. ψυγεία, κλιματιστικά, πλυντήρια). Η σύνδεση όλο και περισσότερων data centers στο ηλεκτρικό δίκτυο χειροτερεύει συνεχώς την κατάσταση και απαιτεί, μεταξύ άλλων, εκσυγχρονισμό του ηλεκτρικού δικτύου· κάτι που είναι χρονοβόρο και οδηγεί με τη σειρά του σε μεγάλες καθυστερήσεις στη διασύνδεση των data centers. Ο έντονος ανταγωνισμός στο πεδίο της τεχνητής νοημοσύνης οδηγεί συχνά στην παράκαμψη περιβαλλοντικών κανονισμών και της νομοθεσίας, τόσο για την κατασκευή όσο και για τη λειτουργία των data centers. Χαρακτηριστικό παράδειγμα: το data center της xAI στο Μέμφις των ΗΠΑ, το οποίο αντιμετώπισε τις καθυστερήσεις στη διασύνδεση με το ηλεκτρικό δίκτυο με χρήση φορητών γεννητριών μεθανίου, και το οποίο κατηγορείται για παραβίαση των περιβαλλοντικών κανονισμών και σημαντική μόλυνση του αέρα σε μια μεγάλη περιοχή γύρω από αυτό. Σε αυτές τις περιπτώσεις, το θύμα συνήθως είναι οι φτωχές κοινότητες στην περιοχή των οποίων θα κατασκευαστεί ένα data center, γιατί τέτοιες κοινότητες έχουν φθηνή γη, φθηνά εργατικά χέρια και μικρές δυνατότητες αντίστασης, ακόμα και όταν οι μεγάλες τεχνολογικές εταιρίες παραβαίνουν πολεοδομικούς ή περιβαλλοντικούς κανονισμούς.
Επίσης, τα data centers είναι ευαίσθητα σε παραμορφώσεις της τάσης στο ηλεκτρικό δίκτυο. Γι’ αυτό, όταν ανιχνεύσουν έστω και μικρές παραμορφώσεις μπορεί να αποκόψουν τον εαυτό τους από το δίκτυο, χρησιμοποιώντας τις δικές τους γεννήτριες. Αυτό αφαιρεί ένα σημαντικό τμήμα του φορτίου από το ηλεκτρικό δίκτυο, διαταράσσοντάς το ακόμα περισσότερο, κάτι που μπορεί να οδηγήσει σε αλυσιδωτή αποκοπή αρκετών data centers από αυτό, αλλά ακόμα και «πτώση» του δικτύου. Πέρα από όλα αυτά, όπως είναι εύκολο να φανταστεί κανείς, οι ανάγκες αυτές σε ηλεκτρική ενέργεια είναι δύσκολο να καλυφθούν από το ίδιο ηλεκτρικό δίκτυο και τα ίδια εργοστάσια ηλεκτρικής ενέργειας που προμηθεύουν πόλεις και βιομηχανίες. Για όλους τους παραπάνω λόγους, η πυρηνική τεχνολογία φαίνεται να έρχεται ξανά στο προσκήνιο· τόσο στην κλασική της μορφή, όσο και με την ανάπτυξη μικρών αρθρωτών αντιδραστήρων (SMRs), έτσι ώστε οι εταιρίες να κατασκευάσουν τα δικά τους ιδιωτικά μίνι εργοστάσια παραγωγής ενέργειας κοντά στα τεράστια data centers τους. Παράλληλα με την πυρηνική ενέργεια, ερευνώνται και δοκιμάζονται και άλλες τεχνολογίες παραγωγής ενέργειας, όπως η χρήση υδρογόνου, πυρηνικής σύντηξης και γεωθερμίας, με τεράστιες επενδύσεις στον τομέα αυτό και από τις μεγάλες τεχνολογικές εταιρίες (π.χ. Google, Amazon, OpenAI, Oracle, Meta, Microsoft).
Δεν είναι τυχαίο ότι μεγάλοι τεχνολογικοί κολοσσοί ερευνούν ακόμα και σενάρια τα οποία παλιότερα θα ανήκαν στη σφαίρα της επιστημονικής φαντασίας, όπως τη μετακίνηση πολλών data centers σε περιοχές κοντά στους πόλους, κάτω από την επιφάνεια της θάλασσας ή ακόμα και στο διάστημα. Οι περισσότερες όμως δεν είναι ρεαλιστικές. Τουλάχιστον, για την ώρα.
Α7. Τα όρια της τεχνητής νοημοσύνης – Πόσο μπορεί να εξελιχθεί [25][26][27][28][29][30][31][32][33][34][35][36][37][38][39][40][41][42]
Ένα από τα μεγαλύτερα ερωτήματα στον τομέα της τεχνητής νοημοσύνης είναι το κατά πόσο μπορούμε να κατασκευάσουμε ένα μηχάνημα το οποίο να έχει νοημοσύνη ισότιμη ή ανώτερη από αυτή του ανθρώπου. Οι απόψεις εδώ μοιράζονται σε δύο κατηγορίες.
Η πρώτη κατηγορία θεωρεί ότι κάτι τέτοιο είναι, ή φαίνεται να είναι, αδύνατο. Αυτό βασίζεται στο πώς πιστεύουν ότι λειτουργεί η ανθρώπινη νοημοσύνη (σε φυσικό ή μεταφυσικό επίπεδο), τι ικανότητες έχει, και πώς αξιολογούμε την πορεία της τεχνολογικής ανάπτυξης. Από επιστημονικής πλευράς, θεωρούν ότι σε όλες τις τεχνολογίες που έχουμε αναπτύξει μέχρι σήμερα δεν διαφαίνεται η παραμικρή ένδειξη ότι μια μηχανή μπορεί να καταλάβει τι κάνει και γιατί το κάνει ή ότι μπορεί να καταλάβει έννοιες και βασικές αρχές της Λογικής. Το μόνο που τα εργαλεία τεχνητής νοημοσύνης μπορούν να κάνουν είναι να μιμούνται σε κάποιο βαθμό μερικές από τις συμπεριφορές (λόγια ή ενέργειες) των ανθρώπων, αλλά ποτέ δεν θα μπορέσουν να παρουσιάσουν νοημοσύνη παρόμοια του ανθρώπου, πόσω μάλλον να κρύψουν την πραγματική τους φύση ή να αντικαταστήσουν τον άνθρωπο ως αυτόνομα εξελισσόμενο είδος. Από μεταφυσικής πλευράς, το πρόβλημα εντοπίζεται στην απουσία της ψυχής, η οποία διαδραματίζει κεντρικό ρόλο στη διαμόρφωση της σκέψης και της λογικής του ανθρώπου, και της οποίας η λειτουργία και η σύνθεση δεν μπορεί να αποκωδικοποιηθεί γιατί δεν λειτουργεί με βάση τις αρχές της φυσικής. Για παράδειγμα, υπό το πρίσμα της χριστιανικής διδασκαλίας, κάποιοι (όχι όλοι) από τους λόγους που μια μηχανή δεν θα μπορέσει ποτέ να φτάσει ή να ξεπεράσει τον άνθρωπο λόγω της απουσίας ψυχής είναι:
(α) δεν έχει φαντασία. Άρα, δεν μπορεί να σκεφτεί καινούργιες λύσεις ή τρόπους που δεν περιέχονται στα δεδομένα εκπαίδευσης. Στην ουσία δεν παράγει γνώση. Απλά την ανακτά. Είναι σαν μια εγκυκλοπαίδεια.
(β) δεν έχει συναισθήματα και άρα θα ήταν αδύνατο να κατανοήσει και επομένως να «ευθυγραμμιστεί» (να υπηρετήσει ή να υιοθετήσει) τα ιδανικά και τις επιθυμίες του ανθρώπου. Για παράδειγμα, δεν θα μπορούσε να εκτιμήσει μια ωραία μουσική γιατί τη μουσική δεν την απολαμβάνει το σώμα αλλά η ψυχή του ανθρώπου.
(γ) δεν έχει «νου» και γι’ αυτό δεν μπορεί να αποκτήσει αυτογνωσία· να αναγνωρίσει την ύπαρξή της.
Ακόμα όμως και χωρίς να μπούμε στην περιοχή της μεταφυσικής, υπάρχουν πτυχές της ανθρώπινης νοημοσύνης οι οποίες φαίνεται πως είναι αδύνατο να μοντελοποιηθούν σε μια μηχανή, γιατί εξαρτώνται άμεσα από τον τρόπο που είναι φτιαγμένος ο άνθρωπος.
Για παράδειγμα, είναι αδύνατο για μια μηχανή να αποκτήσει ανθρώπινη προσωπικότητα. Ακόμα και αν προσπαθήσουμε να αντιγράψουμε κάποιες από τις ανθρώπινες νοητικές λειτουργίες, δεν μπορούμε να πάμε μακριά. Μια μηχανή δεν μπορεί να διαμορφώσει ανθρώπινη προσωπικότητα γιατί δεν μπορεί να ζήσει ζωή παρόμοια με ενός ανθρώπου (να μεγαλώσει σταδιακά και να εκπαιδευτεί με ερεθίσματα οπτικά, ηχητικά, αφής, γευστικά και ανθρώπινης αλληλεπίδρασης σε όλες τις ηλικίες). Υπάρχουν εμπειρίες εγγεγραμμένες στη μνήμη ενός ανθρώπου που διαμορφώνουν την προσωπικότητά του, τις οποίες δεν μπορούν να αποκτήσουν ή να μιμηθούν οι μηχανές: η εμπειρία της φωνής και των συναισθημάτων της μητέρας από ένα έμβρυο ή η εμπειρία της γέννησης, η εμπειρία των μητρικής και πατρικής στοργής κατά τα πρώτα χρόνια της ζωής μας, και πολλά άλλα. Ακόμα και αν αγνοήσουμε τη διαμόρφωση της προσωπικότητας κατά τα στάδια της ανάπτυξης του ανθρώπου, δεν πρέπει να ξεχνάμε ότι η λειτουργία του εγκεφάλου επηρεάζεται άμεσα και συνεχώς τόσο από το σώμα, όσο και το περιβάλλον. Χωρίς αυτά τα εξωτερικά αλλά και τα εσωτερικά ερεθίσματα (πώς αισθάνομαι τους μύες μου όταν είμαι πιασμένος, το στομάχι μου όταν βαραίνω από το φαγητό, το κεφάλι μου όταν έχω πονοκέφαλο κ.ο.κ.) ο εγκέφαλος δεν θα μπορούσε να λειτουργήσει κανονικά. Κάτι τέτοιο δεν υπάρχει στην τεχνητή νοημοσύνη. Ένα ρομπότ δεν έχει καν στομάχι για να αλληλεπιδράσει με αυτό.
Ένα άλλο εμπόδιο είναι ότι οι μηχανισμοί επιβράβευσης στον άνθρωπο (οι οποίοι καθοδηγούν σε ένα ποσοστό τις ενέργειές του) είναι αρκετά ασαφείς και δυναμικοί. Μπορεί να μεταβάλλονται ανάλογα με τη διάθεσή του ή με το αν είναι νηστικός, να επηρεάζονται από τα συναισθήματα των άλλων ή και μπορεί να μεταβάλλονται εσκεμμένα από τον ίδιο λόγω των αντιλήψεών του. Γενικά, θα λέγαμε ότι ο άνθρωπος είναι υπερβολικά πολύπλοκος και δεν μπορεί να αντιγραφεί.
Στη δεύτερη κατηγορία ανήκουν όσοι πιστεύουν ότι ο άνθρωπος είναι απλά μια φυσική κατασκευή, μια μηχανή, πιο σύνθετη από τις άλλες, και πως, αργά η γρήγορα, θα την αποκωδικοποιήσουμε και θα φτιάξουμε μια νοήμονα μηχανή η οποία θα περιλαμβάνει ένα είδος νοημοσύνης ισότιμο ή ανώτερο της ανθρώπινης. Αφήνοντας στην άκρη το θέμα της αυτοσυνειδησίας και τα σενάρια περί υπερ-νοημοσύνης (ένα είδος νοημοσύνης τόσο ανώτερο που θα κατέληγε να ήταν ανεξέλεγκτο, συχνά αποκαλούμενο και ως “singularity”), θα ακούσετε συχνά να γίνεται λόγος για το Artificial General Intelligence (AGI). Αν και σε πολλές περιπτώσεις ο όρος AGI τείνει να ερμηνεύεται κατά το δοκούν (ειδικά από CEO εταιριών και ανθρώπους της διαφήμισης οι οποίοι πρέπει να τραβήξουν το ενδιαφέρον επενδυτών στον τομέα της τεχνητής νοημοσύνης), στην ουσία μιλάμε για μια μηχανή η οποία μπορεί να κάνει κάθε είδους εργασία, να μαθαίνει από μόνη της μέσω της εμπειρίας, να κατανοεί έννοιες, να μπορεί να δικαιολογεί τις αποφάσεις της και τις ενέργειές της και να κάνει κάθε είδους πνευματική εργασία, το ίδιο καλά όπως και ο άνθρωπος.
Όμως, ακόμα και πολλοί από τους ερευνητές της τεχνητής νοημοσύνης που ανήκουν στη δεύτερη αυτή κατηγορία, θεωρούν ότι τα τωρινά επιστημονικά επιτεύγματα δεν βρίσκονται καν κοντά στην υλοποίηση ενός AGI. Τα LLMs (τα οποία είναι ό,τι πιο προχωρημένο έχουμε αυτή τη στιγμή που να προσομοιώνει την ανθρώπινη συμπεριφορά) είναι απλά μια τεράστια βάση δεδομένων που κάνει πολύ εύκολη την ανάσυρση πληροφοριών. Δεν μπορούν να καταλάβουν ούτε βασικούς κανόνες λογικής. Γι’ αυτό και τα LLMs (τα chatbots) δεν μπορούν να κάνουν νέες ανακαλύψεις όσο και αν αυξήσουμε το μέγεθός τους. Κάποιοι από τους λόγους για τους οποίους πιστεύουν ότι απέχουμε πάρα πολύ από την υλοποίηση ενός AGI, είναι:
(α) Τα τρέχοντα συστήματα τεχνητής νοημοσύνης (συμπεριλαμβανομένων των ρομποτικών συστημάτων) δεν έχουν καμία κατανόηση του κόσμου (δεν έχουν αυτό που αποκαλείται world model). Για παράδειγμα, δεν μπορούν να προβλέψουν τι θα συμβεί σε οποιαδήποτε περίπτωση (από το να σκουντήξεις ένα βάζο μέχρι το να προσβάλεις τον συνομιλητή σου). Απλά ίσως μπορούν να μαντέψουν τι θα έλεγε κάποιος σχετικά με αυτό (με βάση τα δεδομένα εκπαίδευσης), αν δεν οδηγηθούν σε παραισθήσεις λόγω έλλειψης δεδομένων. Η πραγματική τεχνητή νοημοσύνη (AGI) είναι να μπορεί ένα μηχάνημα να μαθαίνει από την εμπειρία του, να θέλει να μάθει και να ενεργεί για να μάθει. Για να κάνει όμως κάτι τέτοιο θα πρέπει να έχει και έναν τρόπο να συμπεράνει αν αυτό που ζει (που κάνει, που λέει ή που βλέπει να γίνεται) είναι «σωστό» ή «λάθος». Αν του δημιουργεί μια ικανοποίηση. Στον πραγματικό κόσμο, κάνεις ή λες κάτι και βλέπεις το αντίκτυπο αυτής της ενέργειας· και αν αυτό το αντίκτυπο έχει κάποιο θετικό για σένα αποτέλεσμα ή όχι. Έτσι, μπορείς και αποφασίζεις αν αυτό που έκανες ή είπες ήταν το σωστό. Τα LLMs δεν έχουν κάτι τέτοιο. Μπορεί κάποιες φορές οι άνθρωποι να μιμούνται μια συμπεριφορά (πολλές φορές ούτε καν με τον ίδιο ακριβώς τρόπο με τον οποίο την είδαν) αλλά ταυτόχρονα όχι μόνο την αναλύουν (προσπαθούν να καταλάβουν γιατί κάνουμε κάθε τι, αν όντως πρέπει να γίνει έτσι κ.λπ.) αλλά και τη δοκιμάζουν χωρίς να την υιοθετούν απαραίτητα. Το αν θα την ακολουθήσουν εξαρτάται από το αποτέλεσμα της εμπειρίας τους, ακόμα και αν το αποτέλεσμα αυτό δεν είναι το ίδιο με αυτό που βλέπουν να συμβαίνει σε άλλους. Γενικά, η διαμορφωμένη ανθρώπινη συμπεριφορά δεν είναι μίμηση.
Επίσης, τα LLMs δεν μπορούν να κατανοήσουν τον συνομιλητή τους. Μπορεί να κάνουν μια πρόβλεψη για το τι θα πεις αφού σου μιλήσουν, αλλά αυτή η πρόβλεψη δεν είναι βασισμένη στη γνώση του συνομιλητή τους. Και αν τα ξαφνιάσεις με την απάντησή σου, αυτά δεν θα αλλάξουν (ή θα αλλάξουν ελάχιστα και μόνο όταν μιλούν σε εσένα) τον τρόπο με τον οποίο απαντούν. Ακόμα περισσότερο, ίσως η απάντησή σου να προσαρμόσει λίγο τη δική τους ανταπόκριση, αλλά δεν θα έχουν μάθει τίποτα για σένα. Δεν αποκτούν γνώση του κόσμου.
(β) Τα LLMs δεν έχουν κάποιο σκοπό ζωής. Είναι ένα σύστημα το οποίο προσπαθεί να προβλέψει την επόμενη λέξη που πρέπει να ειπωθεί, και απλά είναι «χαρούμενο» όταν το κάνει σωστά. Δεν προσπαθεί όμως να πετύχει κάτι στον κόσμο αυτό. Να αλλάξει τον κόσμο προς μία κατεύθυνση. Τέτοιες έννοιες ή στόχοι είναι εξαιρετικά δύσκολο να μοντελοποιηθούν ώστε να προγραμματιστούν σε μια μηχανή, αλλά είναι συχνά απαραίτητοι, τόσο για την επέκταση των γνώσεων όσο και για την ικανοποιητική εκτέλεση μιας εργασίας που μας ανατίθεται από άλλους (συχνά η ανάθεση μιας εργασίας υπονοεί/υποκρύπτει και άλλες επιθυμίες).
(γ) Η νέα γενιά συστημάτων τεχνητής νοημοσύνης μπορεί να έχει αυξήσει τις δυνατότητές της κατά πολύ, σε σχέση με την προηγούμενη γενιά που δεν χρησιμοποιούσε νευρωνικά δίκτυα, αλλά έχει αυξήσει τρομακτικά και τις απαιτήσεις της σε ενέργεια και αποθηκευτικό χώρο. Από αυτή την οπτική γωνία, θα λέγαμε ότι δεν φαίνεται όχι να φτάνει, αλλά ούτε καν να πλησιάζει τον τρόπο λειτουργίας της ανθρώπινης νοημοσύνης.
(δ) Η εκπαίδευση των σύγχρονων νευρωνικών δικτύων (όπως αυτό του ChatGPT) απαιτεί τεράστια data centers, αρκετούς μήνες και σημαντικές ποσότητες ενέργειας μέχρις ότου δημιουργηθεί το βασικό μοντέλο του νευρωνικού δικτύου που θα χρησιμοποιηθεί. Αφού ολοκληρωθεί η εκπαίδευση, το μοντέλο αυτό μικραίνει σε μέγεθος ώστε να μπορεί να τοποθετηθεί στα επί μέρους data centers ανά τον κόσμο και να προσφέρει τις σχετικές υπηρεσίες. Γι’ αυτό τον λόγο, μετά τη χρονοβόρα φάση της εκπαίδευσης, συστήματα όπως τα LLMs δεν μπορούν να συνεχίσουν να «μαθαίνουν» με τον ίδιο ρυθμό.
Δείτε επίσης: Τεχνητή Νοημοσύνη - Μέρος Β: Πώς η τεχνητή νοημοσύνη αλλάζει την οικονομία και την κοινωνία μας
Αναφορές:
[1]. «The Alignment Problem: Machine Learning And Human Values», Brian Christian, Ww Norton & Co, 2021
[2]. Large Language Model, Wikipedia, 2025
[3]. «ChatGPT explained completely», Kyle Hill, 2024
[4]. «Transformers, the tech behind LLMs | Deep Learning Chapter 5», 3Blue1Brown, 2024
[5]. «Attention in transformers, step-by-step | Deep Learning Chapter 6», 3Blue1Brown, 2024
[6]. «How might LLMs store facts | Deep Learning Chapter 7», 3Blue1Brown, 2024
[7]. «But how do AI images and videos actually work?», 3Blue1Brown and Welch Labs, 2025
[8]. «Diffusion Models for AI Image Generation», IBM Technology, 2025
[9]. «How AI Image Generators Work (Stable Diffusion / Dall-E)», Computerphile, 2022
[10]. «How AI Image Generation Works: DALL-E, Stable Diffusion, Midjourney», AltexSoft, 2024
[11]. «How AI 'Understands' Images (CLIP)», Computerphile, 2024
[12]. «Why Large Language Models Hallucinate», IBM Technology, 2023
[13]. «Why Language Models Hallucinate», 2025
[14]. «Why AI hallucinations are here to stay | Ep. 151», TECHtalk, 2024
[16]. «The human interface: When machines become more human than humans», Gari Johnson, Gari Johnson Books, 2025
[17]. «Internet energy consumption: data, models, forecasts?» Thunder Said Energy
[18]. «How much electricity will AI need?», International Energy Agency, 2025
[19]. «How AI uses our drinking water - BBC World Service», BBC World Service, 2025
[20]. «We Went to the Town Elon Musk Is Poisoning», More Perfect Union, 2025
[21]. «How AI is Ruining the Electric Grid», Wendover Productions, 2025
[22]. «Managing Harmonic Distortion from Data Centers», Dynamic Ratings, 2025
[23]. «How Google, Microsoft And Amazon Are Racing To Solve The AI Energy Crisis», CNBC, 2025
[24]. «Energy Demand in AI», Caleb Writes Code, 2025
[26]. «Τεχνητή Νοημοσύνη. Το παιχνίδι αλλάζει.», NetCast Zone, 2023
[28]. «Πίσω από την τεχνητή νοημοσύνη βρίσκονται εταιρείες που αισχροκερδούν», Ραδιοπαραμυθία, 2023
[29]. «Τεχνητή νοημοσύνη | Οι μηχανές δεν έχουν ιδέα τι είναι τα νοήματα», Ραδιοπαραμυθία, 2023
[30]. «Γιατί η τεχνητή νοημοσύνη δεν είναι ανθρώπινος εγκέφαλος», Μορφωτικό Ίδρυμα ΕΣΗΕΜ-Θ, 2023
[31]. «Richard Sutton – Father of RL thinks LLMs are a dead end», Dwarkesh Patel Podcast, Σεπτ. 2025
[32]. «Why Can't AI Make Its Own Discoveries? — With Yann LeCun», Alex Kantrowitz podcast, 2025
[34]. «NVIDIA CEO Jensen Huang's Vision for the Future», Cleo Abram Podcast, 2025
[35]. «Why full, human level AGI won't happen anytime soon», Go Meta with Oli Sharpe, 2024
[36]. «Oxford’s AI Chair: The Singularity is Bullshit», Johnathan Bi, 2025
[37]. «Richard Feynman: Can Machines Think?», Lex Clips, 2019
[38]. «Terence Tao Says AI Isn't Intelligent—It's Just Exceptionally Clever», 2025
[39]. «Lost in the Hype: AI Will Never Become Conscious | Sir Roger Penrose», This is World, 2025
[40]. «CEO of Microsoft AI:The Next 10 Years Will Change Humanity Forever», Silicon Valley Girl, 2025
[41]. «Sam Altman: The Future of OpenAI, ChatGPT's Origins, and Building AI Hardware», Y Combinator, 2025
[42]. «Sam Altman Shows Me GPT 5... And What's Next», Cleo Abram Podcast, 2025











