
Η αρχιτεκτονική των Μεγάλων Γλωσσικών Μοντέλων (LLMs) - Βοηθητικό Άρθρο
Σε αυτό το βοηθητικό άρθρο θα προσπαθήσουμε να δώσουμε κάποιες περισσότερες πληροφορίες για την δομή και την λειτουργία των LLM με όσο πιο απλά λόγια γίνεται. Τα LLMs αποτελούνται από τα παρακάτω βασικά μέρη:
Embedding: Εδώ η είσοδος χωρίζεται σε μικρότερα μονάδες, τα tokens. Σε μια είσοδο κειμένου, τα tokens μπορεί να είναι λέξεις, τμήματα λέξεων ή σημεία στίξης. Σε μια εικόνα, τα tokens θα είναι μικρά κομμάτια της εικόνας. Κάθε token κωδικοποιείται/αντιστοιχίζεται/αναπαριστάται με ένα αριθμητικό διάνυσμα. Αυτά τα διανύσματα είναι προϋπολογισμένα από ένα τμήμα του νευρωνικού δικτύου που αναλαμβάνει αυτή την αντιστοίχιση και έχει εκπαιδευτεί ξεχωριστά.
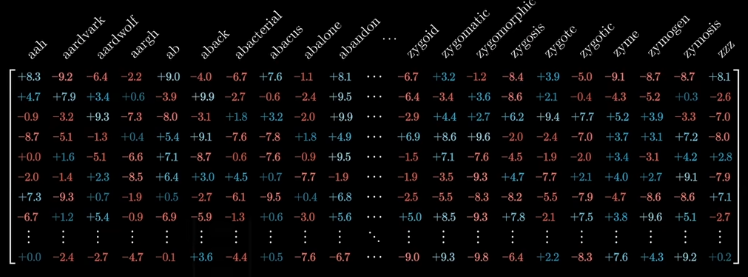
Εάν το μήκος του κάθε διανύσματος είναι 2, σημαίνει ότι το κάθε διάνυσμα αποτελείται από 2 αριθμούς και μπορεί να αναπαρασταθεί γραφικά σε ένα επίπεδο 2-διαστάσεων. Αντίστοιχα, εάν το μήκος είναι 3, το κάθε διάνυσμα αποτελείται από 3 αριθμούς και μπορεί να αναπαρασταθεί γραφικά σε ένα χώρο 3-διαστάσεων.
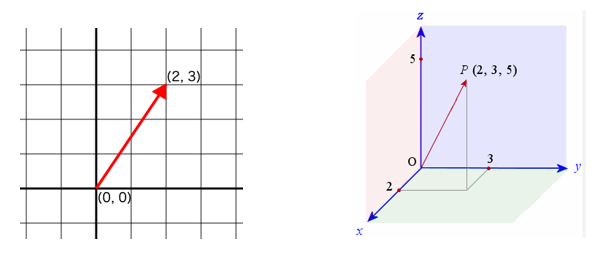
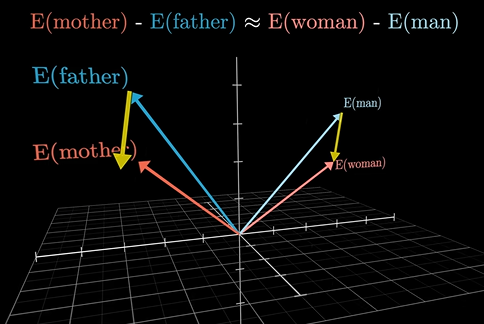
Τα διανύσματα που χρησιμοποιούνται για κάθε λέξη στα LLMs είναι αρκετά μεγάλα (π.χ. σε ένα χώρο 12.000 διαστάσεων για το GPT-3) και δεν επιλέγονται τυχαία. H εκπαίδευση του σχετικού τμήματος του νευρωνικού δικτύπου είναι τέτοια ώστε η κατεύθυνση του κάθε διανύσματος εκφράζει την σημασία της αντίστοιχης λέξης, ως μεμονωμένης λέξης. Οπότε, δύο λέξεις με παρόμοια νόημα, θα αντιπροσωπεύονται από κοντινά διανύσματα. Επίσης, παρόμοια ζεύγη λέξεων θα έχουν παρόμοια απόσταση μεταξύ τους.
Ο αριθμός των παραμέτρων που απαιτεί η μοντελοποίηση αυτού του τμήματος του νευρωνικού δικτύου είναι πολύ μεγάλος. Αν έχουμε 5000 πιθανά token (λέξεις, σημεία στίξης κ.α) στο λεξιλόγιο που χρησιμοποιούμε και το διάνυσμα του κάθε token έχει μήκος 1000, τότε χρειαζόμαστε 5000 x 1000 = 5.000.000 παραμέτρους (βάρη) στο νευρωνικό δίκτυο. Ο λόγος που τα διανύσματα με τα οποία αναπαριστούμε τα tokens είναι τόσο μεγάλα οφείλεται στο γεγονός ότι (α) το κάθε token δεν είναι αναγκαία λέξη αλλά μπορεί να είναι τμήμα μιας λέξης. Οπότε, ο αριθμός των διαφορετικών token που μπορεί να επεξεργαστεί το στάδιο αυτό είναι αρκετά μεγαλύτερος από τον αριθμό των λέξεων του λεξιλογίου της αντίστοιχης γλώσσας, (β) το στάδιο αυτό ανιχνεύει και αποθηκεύει στο διάνυσμα του κάθε token και πληροφορία σχετικά με την χρήση του token (π.χ. είναι αυτόνομο ή αποτελεί πρόθεμα/επίθεμα μιας λέξης).
Attention: Σε αυτό το στάδιο, τα διανύσματα των tokens υπόκεινται σε μια επεξεργασία ώστε το τελικό διάνυσμα κάθε token να εξαρτάται από την θέση του token μέσα στο κείμενο εισόδου, και επομένως από το νόημα που η θέση της λέξης μέσα στο κείμενο παρέχει στην λέξη αυτή. Έτσι, η λέξη "οδηγός" στην πρόταση "ένας οδηγός ταξί" έχει εντελώς διαφορετικό νόημα από ότι στην πρόταση "οδηγός ταξιδίου για την Ελλάδα". Οπότε, αν και το διάνυσμα που θα μας δώσει το πρώτο στάδιο (embedding) για την λέξη "οδηγός" θα είναι ίδιο και στις δύο περιπτώσεις, μετά το δεύτερο στάδιο το διάνυσμα της λέξης αυτής θα είναι εντελώς διαφορετικό στην κάθε περίπτωση. Άρα, βλέπουμε ότι η τοπική πληροφορία (οι λέξεις που προηγούνται ή έπονται μέσα στην ίδια πρόταση) επηρεάζει το νόημα της λέξης. Το ίδιο συμβαίνει και με την μη-τοπική πληροφορία. Η θέση μιας λέξης μέσα σε ολόκληρο το κείμενο εισόδου της προσδίδει επίσης μια πληροφορία/σημασία (π.χ. η λέξη «υποβρύχιο» μέσα σε ένα κείμενο που μιλάει για έναν πόλεμο έχει εντελώς διαφορετική σημασία από τον λέξη «υποβρύχιο» σε ένα κείμενο που μιλάει για παραδοσιακά γλυκίσματα). Επίσης, η λέξη «υποβρύχιο» σε ένα κείμενο που περιέχει τη φράση «το υποβρύχιο Κόκκινος Οκτώβρης» (πιθανότατα από μια περιγραφή της ταινίας «Κόκκινος Οκτώβρης» -αναφέρεται σε ένα συγκεκριμένο υποβρύχιο) έχει πολύ διαφορετικό νόημα από την λέξη «υποβρύχιο» σε κείμενο που περιέχει τη φράση «το νέο υποβρύχιο του βασιλικού πολεμικού ναυτικού» (πιθανότατα από ειδησεογραφικό κείμενο - αναφέρεται και πάλι σε συγκεκριμένο υποβρύχιο αλλά διαφορετικό από τον Κόκκινο Οκτώβρη και σε άλλο είναι το χρονολογικό πλαίσιο αναφοράς κ.λπ.).
Όπως είδαμε στα παραδείγματα αυτά, τόσο η γενικότερη πληροφορία (π.χ. θεματολογία ολόκληρου του κειμένου) όσο και η ειδικότερη/τοπική πληροφορία (π.χ. νόημα της πρότασης), μπορούν να αλλάξουν την επίδραση που θα ασκήσει ένα token στο υπολογισμό της εξόδου. Γι αυτό, και η τοπική και η γενικότερη πληροφορία επηρεάζουν την κωδικοποίηση του token. Στην ουσία, το στάδιο αυτό εκτελείται για κάθε token και σκοπός του είναι διορθώση την αρχική σημασία που έχει δοθεί σε αυτό το token με την αληθινή του σημασία χρησιμοποιώντας τα συμφραζόμενα. Ή, με άλλα λόγια, να διορθώσει την κατεύθυνση του διανύσματος, με βάση τα υπόλοιπα διανύσματα. Ο λόγος που τα διανύσματα των tokens έχουν τόσο μεγάλο μήκος οφείλεται στον όγκο της πληροφορίας που μεταφέρει αυτή η λέξη. Όχι μόνο ως μεμονωμένη λέξη αλλά και από τα συμφραζόμενα. Για παράδειγμα, η λέξη «υποβρύχιο» μπορεί να έχει πολλές διαφορετικές σημασίες ανάλογα με το αν μιλάμε για «το γλυκό υποβρύχιο», το «υποβρύχιο ψάρεμα», «τα πυρηνικά υποβρύχια», το «υποβρύχιο Κόκκινος Οκτώβρης», ένα «υποβρύχιο καλώδιο μεταφοράς ενέργειας» κ.λπ. Το τελικό διάνυσμα της λέξης εκφράζει το νόημα της λέξης μέσα σε ένα συγκεκριμένο πλαίσιο, το οποίο καθορίζεται από το κείμενο στο οποίο η λέξη περιέχεται. Ολόκληρο το κείμενο. Όχι μόνο την πρόταση στην οποία περιέχεται.
Η διαδικασία αυτή γίνεται σε στάδια. Για παράδειγμα, αρχικά μπορούμε να ανιχνεύσουμε αν ένα συγκεκριμένο token είναι ουσιαστικό, επίθετο, αντωνυμία κ.ο.κ. Ας μην ξεχνάμε ότι πολλές φορές τα επίθετα χρησιμοποιούνται και ως ουσιαστικά (π.χ. «Το μπλε είναι το αγαπημένο μου χρώμα.») Στην συνέχεια, θα μπορούσαμε να κοιτάξουμε αν υπάρχουν επίθετα τα οποία να προηγούνται κάποιου ουσιαστικού και τροποποιούν το νόημά του. Για παράδειγμα, η σημασία της λέξης «αυτοκίνητο» στην φράση «Ο Γιώργος αγόρασε καινούργιο αυτοκίνητο» είναι διαφορετική από την σημασία της στην φράση «Ο Γιώργος αγόρασε ένα μικρό κόκκινο αυτοκίνητο». Σε κάθε μία από τις δύο περιπτώσεις, το διάνυσμα της λέξης «αυτοκίνητο» θα είναι διαφορετικό. Η αναπροσαρμογή του νοήματος ενός token με βάση τα υπόλοιπα εξαρτάται όχι μόνο από την σημασία των token (π.χ. αν κάποια από αυτές είναι επίθετο ή ουσιαστικό) αλλά και από την θέση τους (π.χ. ένα επίθετο που πρηγείται ενός ουσιαστικού θα επηρεάσει την σημασία του ουσιαστικού πολύ περισσότερο από ένα επίθετο που ακολουθεί το ουσιαστικό).
Μια κατεύθυνση μέσα σε αυτόν τον πολυδιάστατο χώρο εκφράζει ένα είδος πληροφορίας. Γι αυτό μετατοπίζοντας την διεύθυνση ενός διανύσματος αλλάζουμε την πληροφορία που περιέχεται σε αυτό. Και επειδή ο χώρος αυτός έχει τόσες πολλές διαστάσεις, η πληροφορία που μπορεί να εκφραστεί είναι πολύ πλούσια. Μπορεί να έχει να κάνει με τι είδους είναι ένα «κτίριο» ή το που βρίσκεται αυτό το κτίριο ή σε ποια χρονολογία χτίστηκε και από ποιόν, μέχρι συναισθήματα ή την ιστορία στην οποία συμμετέχει ένα πρόσωπο.
Αξίζει να τονίσουμε εδώ ότι οι έννοιες που μπορούν να απεικονιστούν σε ένα διάνυσμα διάστασης Ν είναι πολύ περισσότερες από όσες θα περιμέναμε. Έχει αποδειχθεί πως αν χαλαρώσουμε τον αυστηρό περιορισμό κάθε διάσταση του χώρου να είναι κάθετη σε όλες τις υπόλοιπες διαστάσεις και δεχθούμε πως η γωνία μεταξύ δύο διαστάσεων μπορεί να είναι σχεδόν κάθετη (π.χ. από 89ο έως 91ο), τότε ο αριθμός των διαστάσεων που μπορούμε να ορίσουμε με το ίδιο διάνυσμα αυξάνει εκθετικά με το μήκος του διανύσματος και όχι γραμμικά!
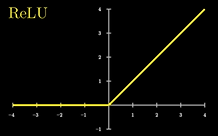
MultiLayer Perceptrons (MLPs): Στο στάδιο αυτό, κάθε διάνυσμα υπόκειται μια ανεξάρτητη από τα υπόλοιπα διανύσματα επεξεργασία ώστε να εξαχθούν από αυτό κάποιες ιδιότητες (features) γι αυτό. Όπως, σε ποια γλώσσα αντιστοιχεί, αν αναφέρεται σε κάποιο πρόσωπο, αν είναι ένα συναίσθημα, αν αφορά συγκεκριμένη χρονική περίοδο ή χρονολογία κ.λπ. Το αποτέλεσμα της επεξεργασίας κάθε διανύσματος είναι ένα άλλο διάνυσμα που περιγράφει κατά πόσο το αρχικό διάνυσμα έχει κάθε ένα από τα χαρακτηριστικά που αναζητούμε. Για τα χαρακτηριστικά που η συσχέτιση με το διάνυσμα του token δεν είναι σημαντική, η πληροφορία ξεσκαρτάρεται (η τιμή μηδενίζεται) ώστε να απλοποιήσουμε την επίδρασή τους.
π.χ εφαρμόζοντας μια συνάρτηση ενεργοποίησης η οποία μηδενίζει αρνητικές τιμές
Τα αρχικά στάδια εξάγουν πιο τοπική/βασική πληροφορία και όσο προχωράμε το είδος της πληροφορίας που εξάγεται γίνεται και πιο γενικό/πολύπλοκο. Σε κάποια σημεία η πληροφορία που έχει εξαχθεί συμπυκνώνεται σε διανύσματα λιγότερων διαστάσεων, έτσι ώστε κάθε τιμή στο διάνυσμα αυτό εκφράζει ένα συνδυασμό πληροφοριών. Τα Attention και MLP τμήματα επεξεργασίας μπορεί να είναι πολλαπλά και να εναλλάσσονται μέχρι να επιτευχθεί ικανοποιητική επεξεργασία.
Στο τελικό στάδιο του MLP κάθε διάνυσμα περιέχει όλη την πληροφορία που καταφέραμε να ανιχνεύουμε για το νόημα του αντίστοιχου token μέσα από το κείμενο εισόδου. Τα τελικά αυτά διανύσματα των tokens χρησιμοποιούνται για να υπολογίσουμε την πιθανότητα κάθε λέξης του λεξιλογίου μας να είναι η επόμενη λέξη. Οι πιθανότητες αυτές είναι σε μεγάλο βαθμό προϋπολογισμένες μέσω της εκπαίδευσης του LLM. Η λέξη με την μεγαλύτερη πιθανότητα επιλέγεται εφ' όσον όλες οι υπόλοιπες έχουν πολύ μικρότερη πιθανότητα. Αν αρκετές λέξεις ανταγωνίζονται για την πρώτη θέση, τότε το LLM μπορεί να επιλέξει διαφορετική κάθε φορά, ώστε να εισάγει ένα βαθμό πρωτοτυπίας στις απαντήσεις του.
Unembedding: Στο στάδιο αυτό μετατρέπουμε το αριθμητικό διάνυσμα του token εξόδου σε κείμενο.
Αφού τοποθετήσουμε το token εξόδου στο τέλος του κειμένου εισόδου, χρησιμοποιούμε το νέο κείμενο (κείμενο εισόδου + token εξόδου) ως νέα είσοδο και επαναλαμβάνουμε τους υπολογισμούς ώστε να υπολογίσουμε το επόμενο token εξόδου.





